
Challenges of Exascale Computing by Nvidia Chief Scientist (45 pages)
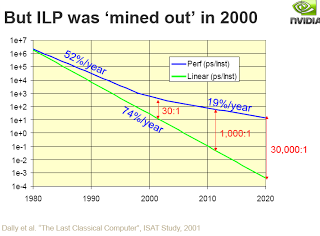
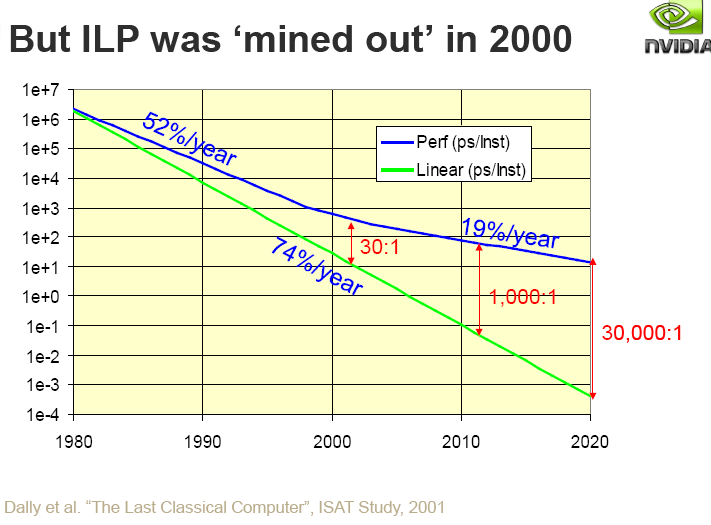
Instruction level parallelism (ILP) was mined out in 2000.
Historic scaling is at an end! To continue performance scaling of all sizes of computer systems requires addressing two challenges:Power and Programmability. Much of the economy depends on this.


Now voltage is held nearly constant
Halve L and get 2x the capability for the same power in ¼ the area
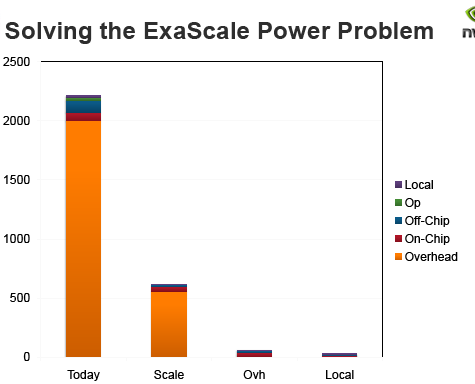
Addressing The Power Challenge Locality and Overhead
* Locality
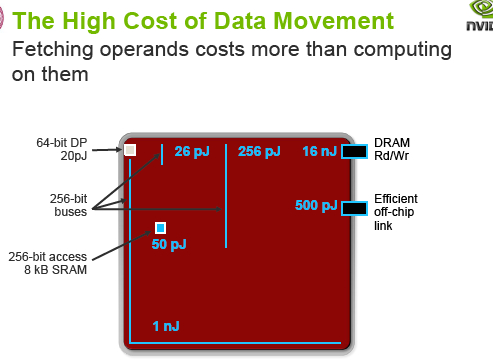
– Bulk of data must be accessed from nearby memories (2pJ) not across the chip (150pJ) off chip (300pJ) or across the system (1nJ)
– Application, programming system, and architecture must work together to exploit locality
* Overhead
– Bulk of execution energy must go to carrying out the operation not scheduling instructions (100x today)
– We must build efficient cores –where the bulk of the energy is spent on operations, not overhead.

Its not about the FLOPS
Its about data movement
Algorithms should be designed to perform more work per unit data movement.
Programming systems should further optimize this data movement.
Architectures should facilitate this by providing an exposed hierarchy and efficient communication.
Locality at all Levels
* Application
– Optimize data movement, not number of operations
– E.g., recomputevalues rather than fetching them
* Programming system
– Optimize subdivision
– Choose when to exploit spatial locality with active messages
– Choose when to compute vs. fetch
* Architecture
– Exposed storage hierarchy
– Efficient communication and bulk transfer

Fundamental and Incidental Obstacles to Programmability
* Fundamental
– Expressing 10^9 way parallelism
– Expressing locality to deal with over 100:1 global:localenergy
– Balancing load across 10^ 9 cores
* Incidental
– Dealing with multiple address spaces
– Partitioning data across nodes
– Aggregating data to amortize message overhead

If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.