

Big data analysis additionally is driving the demand for even faster, more effective, and also energy-saving computer clusters. The number of processors per system has now reached the millions and looks set to grow even faster in the future. Yet something has remained largely unchanged over the past 20 years and that is the programming model for these supercomputers. The Message Passing Interface (MPI) ensures that the microprocessors in the distributed systems can communicate. For some time now, however, it has been reaching the limits of its capability.
Development work has resulted in the Global Address Space Programming Interface – or GPI – which uses the parallel architecture of high-performance computers with maximum efficiency.
GPI is based on a completely new approach: an asynchronous communication model, which is based on remote completion. With this approach, each processor can directly access all data – regardless of which memory it is on and without affecting other parallel processes.
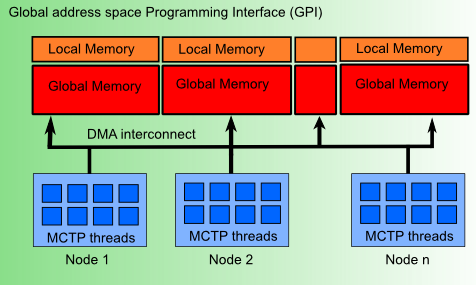
Like the programming model of MPI, GPI was not developed as a parallel programming language, but as a parallel programming interface, which means it can be used universally. The demand for such a scalable, flexible, and fault-tolerant interface is large and growing, especially given the exponential growth in the number of processors in supercomputers.
Initial sample implementations of GPI have worked very successfully: “High-performance computing has become a universal tool in science and business, a fixed part of the design process in fields such as automotive and aircraft manufacturing,” says Dr. Christian Simmendinger. “Take the example of aerodynamics: one of the simulation cornerstones in the European aerospace sector, the software TAU, was ported to the GPI platform in a project with the German Aerospace Center (DLR). GPI allowed us to significantly increase parallel efficiency.”
Even though GPI is a tool for specialists, it has the potential to revolutionize algorithmic development for high-performance software. It is considered a key component in enabling the next generation of supercomputers – exascale computers, which are 1,000 times faster than the mainframes of today.
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.