

System designer for the multiple iterations of the Tianhe machines, Dr. Yutong Lu, revealed that the Tianhe-2 supercomputer will be receiving its upgrade in 2016. However, due to the trade restrictions, they won’t be boosting their supercomputer with more Xeon Phi cores. Rather, the novel architecture they developed will deliver the system the extra 45 petaflops it needs to continue its reign at the top of the list for the foreseeable future.
A rapt audience, including The Platform, listened to Lu during a session at the International Supercomputing Conference in Germany as Lu outlined the digital signal processor (DSP) basis for the new chips that will extend Tianhe-2A (the name of the upgraded system) within the next year instead of by the end of 2015, as was originally planned.
It will be the first 100 petaflop peak capable machine in history.
Dr. Lu has overseen the evolution of the Tianhe machines, beginning with the Tianhe-1A supercomputer, which took the world by surprise, toppling the dominant Titan system at Oak Ridge National Laboratory in 2013. She told the audience this week that the team at NUDT believe in the future of heterogeneous architectures and will move ahead as planned with the upgrade leveraging this new accelerator, which one can only imagine must have already been in development at NUDT for some time if the upgraded machine can have its new chips within one year.

They will probably use latest generation Xeon “Haswell” host processors with the addition of their China Accelerator. Although it is not unlikely that by the time the upgraded machine emerges it could sport a processor from ShenWei or another Chinese chip design and manufacturing house.
Lu says that the team at NUDT is still on track to continue work on key applications that consume large numbers of the machine’s 3,120,000 cores (a combination of two Intel “Ivy Bridge” processors and three Xeon Phi coprocessors). She pointed to application successes in computational fluid dynamics (CFD), which is the most popular code area for Tianhe-2. From scramjet combustion and large passenger and cargo aircraft simulations, the teams have scaled their code past the million core mark with parallel efficiency of close to 80%, Lu says.
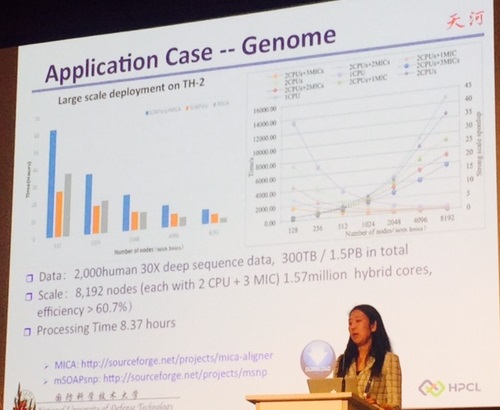
Other research areas, including genomics (population genetics and biomedical applications are two Lu described in detail) are also running on TIanhe-2 with unprecedented levels of scalability and parallel efficiency, validating the “neo-heterogeneous” approach (the combination of SMP processors and many core accelerators) as the continued path forward for China’s supercomputers.
The Matrix2000 GPDS performance for both single and double precision is around 4.8 single, 2.4 double teraflops for one card and it uses a tiny power envelope. IT will support high bandwidth memory as well as PCIe 3.0. In other words, it gives GPUs and Xeon Phi a run for the money. Each of the optimized GPDSP cores (with both scalar and vector units, dedicated vector memory, and VLIW capabilities) are integrated into one “supernode” as system designer for the Tianhe machines at NUDT, Dr. Yutong Lu calls it, via a high speed, non-blocking network on chip to connect these supernodes at 4 terabytes per second.
From a systems level, China is working hard to develop its own custom blend of homegrown technologies that could, at any moment, carve U.S. tech vendors out of the picture entirely. The best example on the Tianhe machine is the one that was grossly overlooked when the system was announced. The custom TH2 interconnect is the key to the system’s performance—and this is entirely unique to this machine


SOURCE – Articles by Nicole Hemsoth at ThePlatform.net

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.