

Demi explains the policy and value neural networks.
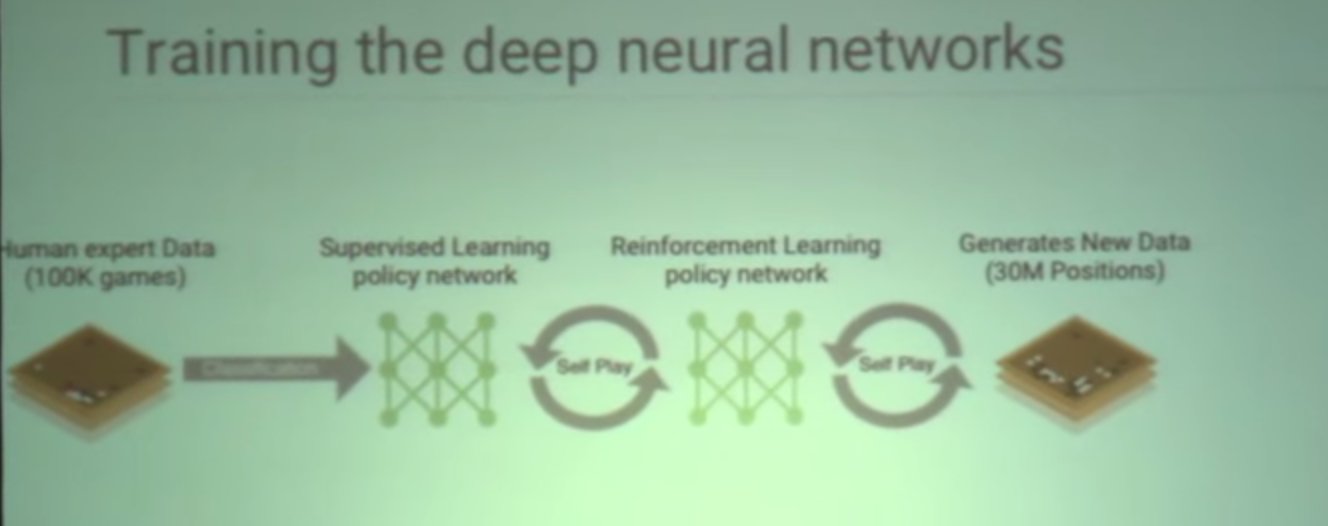
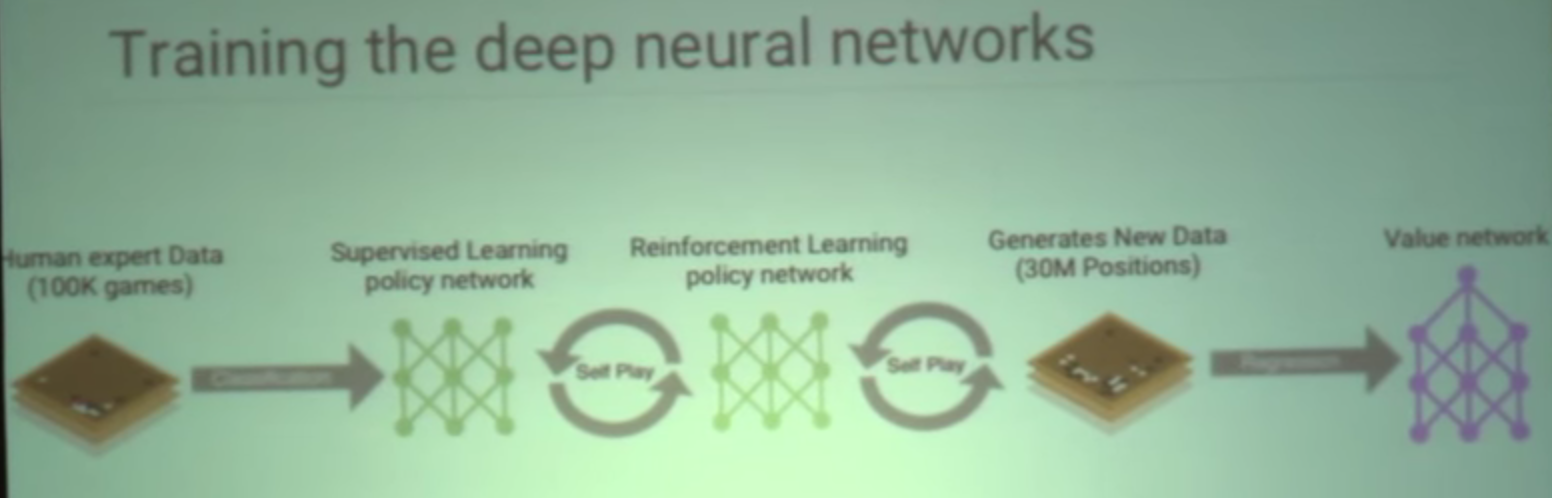
Policy is neural network trained to make reasonable moves based upon supervised learning of 100,000 games.
Value network is built from tens of millions of games to be able to determine what winning positions are.
The value scoring of positions was previously believed to be impossible.
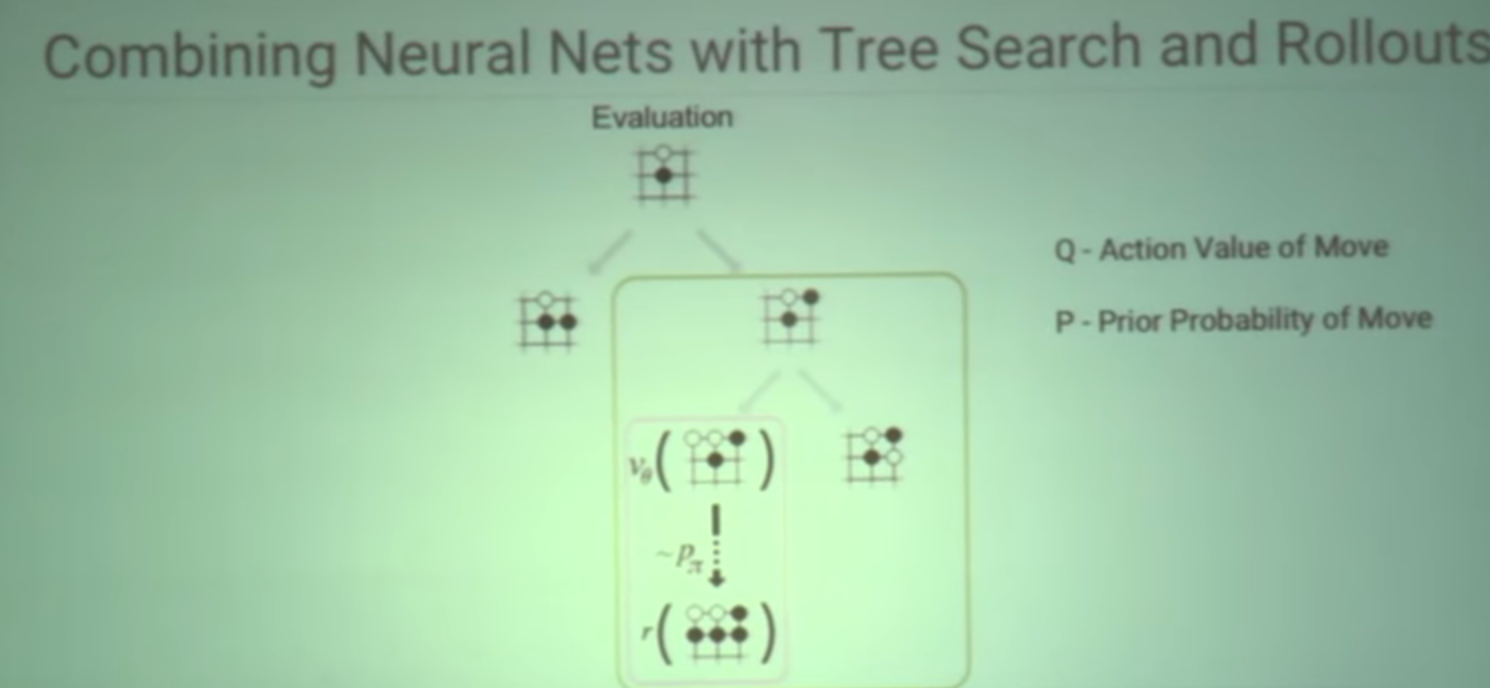
Alphago used policy to reduce the breadth of search
Alphago used value network to reduce the depth of the search for good moves.
Alphago also uses fast rollouts to play a few thousand games to determine statistics for which moves are good.
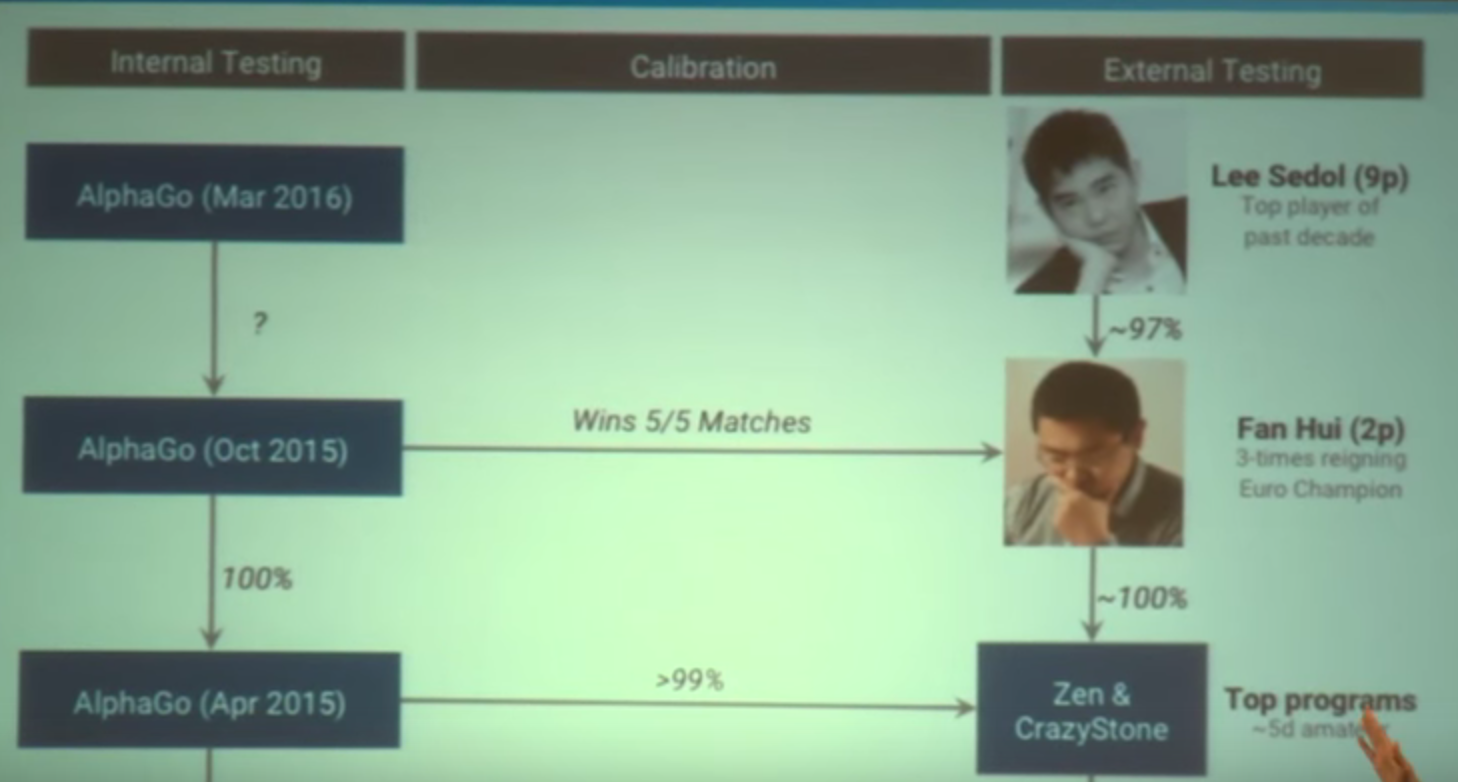
The Alphago program is improving by several levels every few months.




Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.