

Intel has the only fully integrated silicon photonics solution with Intel’s hybrid laser technology, featuring greater than 90% coupling efficiency Intel’s optical connectivity interoperates with other technologies, such as Smart-NICs, FPGAs, and Intel® Omni-Path Architecture fabric


“Electrons running over network cables won’t cut it,” said Bryant in her keynote address, “Intel is the only one to build the laser on silicon and therefore we are the first to light up silicon. We integrate the laser light emitting material, which is indium phosphide onto the silicon, and we use silicon lithography to align the laser with precision. This gives us a cost advantage because it is automatically aligned versus manually aligned as with traditional silicon photonics.”
The two QSFP28 optical transceivers, now shipping in volume, are based on industry standards at 100G for switch, router, and server use, notes Intel. The 100G PSM4 (Parallel Single Mode fiber 4-lane) optical transceiver features up to 2 kilometer reach on parallel single-mode fiber and the 100G CWDM4 (Coarse Wavelength Division Multiplexing 4-lane) optical transceiver offers up to 2 kilometer reach on duplex single-mode fiber.
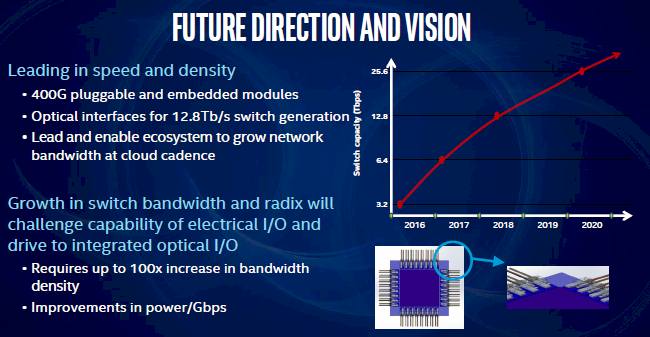
The first Intel Silicon Photonics products will fulfill the need for faster connections from rack to rack and across the datacenter, said Bryant. “As the server network bandwidth increases from 10 Gig to 25 Gig to 50 Gig, optics will be required down into the server as well. We see a future where silicon photonics, optical I/O is everywhere in the datacenter and then integrated into the switch and the controller silicon. Our ability to run optics on silicon gives the end user a compelling benefit.”
There is no way copper can scale beyond 100 Gbps.
It gives a mechanism to scale to even higher bandwidth — up to 400 Gbps in the near future.
Intel Puts AI-focused ‘Knights Mill’ on Phi Roadmap

Bryant also revealed that the next-generation Xeon Phi product would not be the 10nm “Knights Hill” that we’d been expecting but rather a brand-new Phi entry, codenamed “Knights Mill” and optimized for deep learning. The surprise Phi product will feature AI-targeted design elements such as enhanced variable precision compute and high capacity memory.
Like its second-gen cousin “Knights Landing,” the third-generation Phi is also a bootable host CPU. “It maintains that onload model,” said Bryant, “but we’ve included new instructions into the Intel instruction set – enhancements for variable precision floating point so the result is you will get even higher efficiency for deep learning models and training of those models complex neural data sets
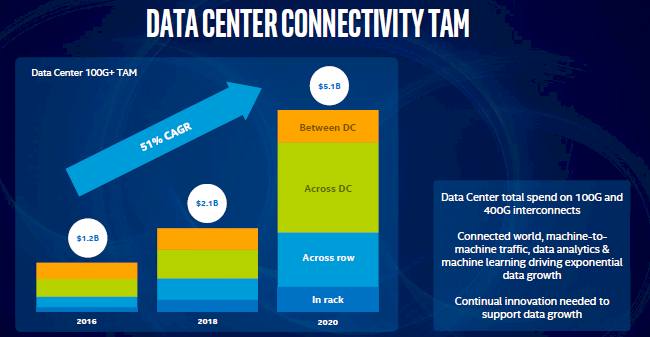
by 2020, we begin connecting the more than 50 billion machines and devices out there we will see the amount of data generated increase by orders of magnitude beyond what we experience today. In fact, connected cars will generate 4 terabytes per day and a connected factory can create more than 1 petabyte per day. For perspective, an MP3 player with one petabyte of songs would play continuously for 2,000 years.
However, data by itself has limited value. When we apply advanced analytics to empower machines with human-like intelligence, we can effect real change. This is where artificial intelligence becomes really exciting. Whether it’s a highly personalized treatment plan for a cancer patient or improved crop yields for feeding the world, gaining deeper insights from this complex data is the key to unlocking more value for businesses and societies.
To help make this a reality, Intel disclosed the next generation of the Intel Xeon Phi processor family (code named Knights Mill), which is focused on high-performance machine learning and artificial intelligence. Knights Mill, expected to be available in 2017, is optimized for scale-out analytics implementations, and will include key enhancements for deep learning training. For today’s machine learning applications, the large memory size of the Intel Xeon Phi processor family helps customers like Baidu make it easier to train their models efficiently.
SOURCE- Intel

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.