

The Teraflop power of the Nvidia tesla supercomputer board, desktop and workstations will be available August 2007.
go to this link to sign up to get more information on buying one
Tesla C870 GPU specifications ($1500 add in card):
– One GPU (128 thread processors)
– 518 gigaflops (peak)
– 1.5 GB dedicated memory
– Fits in one full-length, dual slot with one open PCI Express x16 slot
The GPU is especially well-suited to address problems that can be expressed as data-parallel computations with high arithmetic intensity–in other words when the same program is executed on many data elements in parallel with a high ratio of arithmetic to memory operations.
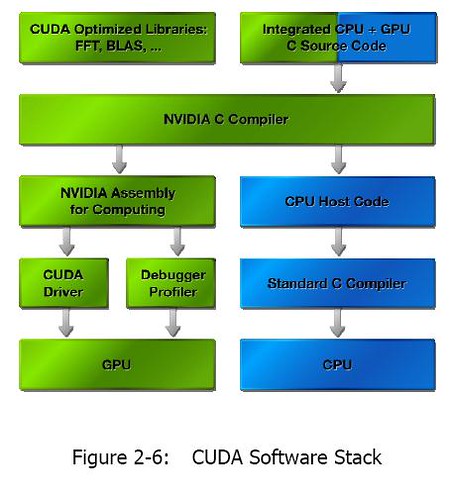
Here is the C programming stack for the NVIDIA supercomputer
In case you did not look at my original article after I updated it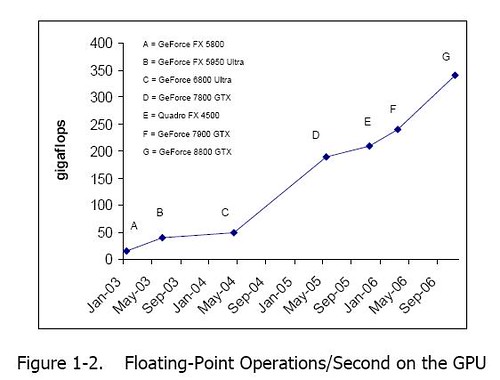
Here is a chart of NVidia crushing Moore’s law. The G92 is expected to be three times faster than the current best chip at 1 teraflop instead of 330Gflop.
Here is a link to the Nvidia 21 page technical brief
Here is a link to the developers info
CUDA (Compute Unified Device Architecture) technology gives computationally intensive applications access to the tremendous processing power of NVIDIA graphics processing units (GPUs) through a revolutionary new programming interface. Providing orders of magnitude more performance and simplifying software development by using the standard C language, CUDA technology enables developers to create innovative solutions for data-intensive problems. For advanced research and language development, CUDA includes a low level assembly language layer and driver interface.
The CUDA Toolkit is a complete software development solution for programming CUDA-enabled GPUs. The Toolkit includes standard FFT and BLAS libraries, a C-compiler for the NVIDIA GPU and a runtime driver. The CUDA runtime driver is a separate standalone driver that interoperates with OpenGL and Microsoft® DirectX® drivers from NVIDIA. CUDA technology is currently supported on the Linux and Microsoft® Windows® XP operating systems.
Google is trying to pursuade ATI and Nvidia to open up their specs on drivers.
There are the reverse engineered Nouveau drivers
Here is an online petition to get Nvidia to opensource their drivers

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.