

Ad Support : Nano Technology Netbook Technology News Computer Software

Yale researchers are developing developing synthetic models of the mammal visual system using custom hardware. Their most recent model uses convolutional neural networks to model the ventral pathway of the mammalian visual system. The goal is to design custom hardware that can implement these models and perform in real-time on megapixel-size cameras as well as state-of-the-art neuromorphic image sensors. The single chip vision system could be used to improve robot navigation into dangerous or difficult-to-reach locations, to provide 360-degree synthetic vision for soldiers in combat situations, or in assisted living situations where it could be used to monitor motion and call for help should an elderly person fall.
Convolutional neural networks or ConvNets are a multi-stage neural network that can model the way brain visual processing area V1, V2, V4, IT create invariance to size and position to identify objects. Each stage is composed of three layers: a filter bank layer, a non-linearity layer, and a feature pooling layer.

The custom hardware makes the system 100 to 1000 60 times faster than conventional and uses 1005 times less electricity than an intel i7.
A Dataflow Computer
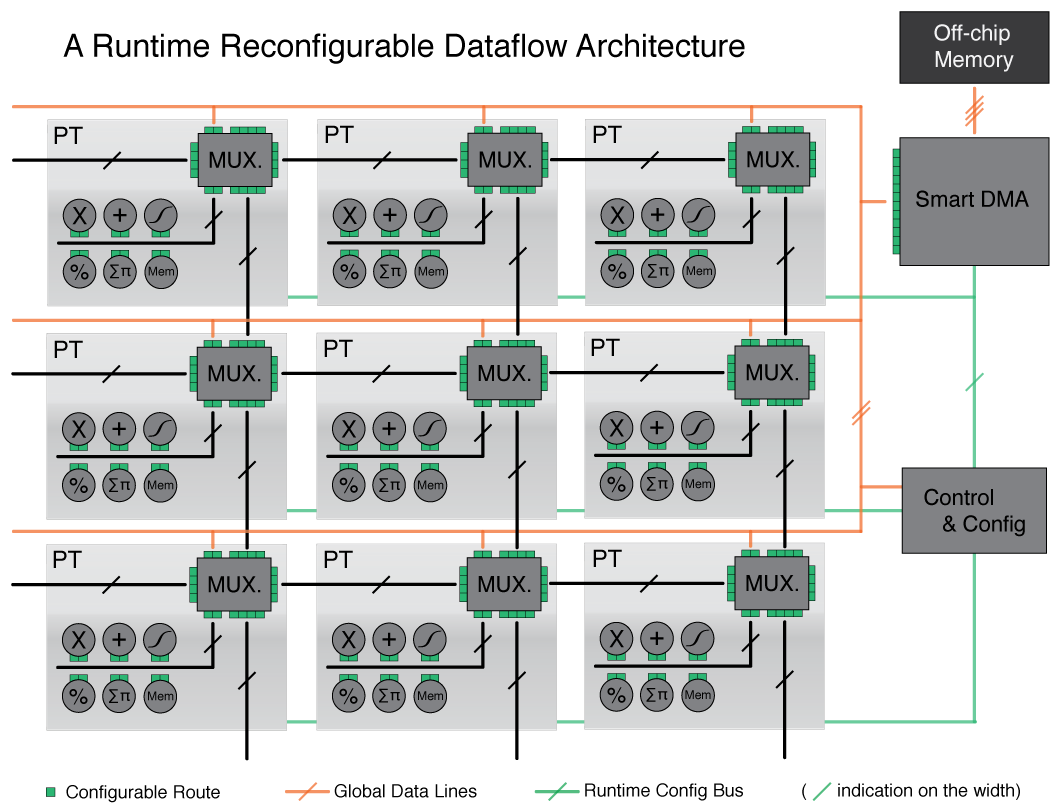
several custom architectures have been proposed to compute models of the human visual system. Our approach to this problem is to provide a general-purpose system that can be programmed like a standard PC. As shown on the figure above, it is based on a runtime reconfigurable 2D grid of computing elements. The reconfiguration capabilities are somewhat similar to those of an FPGA, with the major difference that it can be done at runtime, allowing very diverse computations to be performed on the grid.
The following schema shows a particular configuration of the grid: in that setup, it performs two 2D convolutions with 3×3 kernels, accumulates them on the fly, and then performs a non-linear mapping on the result. Those operations are typical in a convolutional neural network.
Supporting Advertising
Business Success
How to Make Money
Executive Jobs
Paid Surveys

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.