

Sparse coding is a hot area in the field of Deep Learning. Deep learning and sparse coding appears highly promising for increasing the accuracy of image classification and it enables a system to look at tens of millions of images and to classify the information without human supervision. Increasing the accuracy of image and voice recognition can transform the interaction and experience that people have with search systems and artificial intelligence interfaces. A highly accurate voice recognition system means that people can just talk to a computer and not need keyboards and mice. This enables efficient and transformative new form factors for devices. Google, Baidu (dominant search engine in China) and Dwave Systems (adiabatic quantum computers) are all focused on Sparse coding and deep learning.
Dwave systems has a 512 qubit adiabatic quantum computer. They recently wrote up how to solve sparse coding using the Dwave system. The results are comparable to the best conventional systems. If Dwave systems are scaled to 2000 qubits the speed gain expected would be about 500,000 times. This would suggest that Dwave would be the fastest systems for important aspects of artificial intelligence and machine learning.
Dwave used the PiCloud python libraries, which allows us to run hundreds or thousands of parallel jobs to perform the optimization over the weights. As a rough estimate, for the optimization problems generated by MNIST, each optimization using FSS takes about 30 milliseconds, and there are 60,000 of these per iteration of the block descent procedure. If we run serially this is about 30 minutes per iteration. If we use 100 cores, we can send 600 jobs to each core, and get about 100x speed-up, taking the time down to about 20 seconds.
As an interesting aside, Dwave find that our own Python implementation of FSS is about the same in terms of performance as the original MATLAB code provided by Honglak Lee. This was a little surprising as the core computations run in highly optimized compiled code inside MATLAB. This is evidence that the routines within numpy are competitive with MATLAB’s versions for the core FSS computations.
Deep Learning
Deep learning is a sub-field of machine learning (artificial intelligence) that is based on learning several levels of representations, corresponding to a hierarchy of features or factors or concepts, where higher-level concepts are defined from lower-level ones, and the same lower-level concepts can help to define many higher-level concepts.
Deep learning is part of a broader family of machine learning methods based on learning representations. An observation (e.g., an image) can be represented in many ways (e.g., a vector of pixels), but some representations make it easier to learn tasks of interest (e.g., is this the image of a human face?) from examples, and research in this area attempts to define what makes better representations and how to learn them.
Sparse Coding
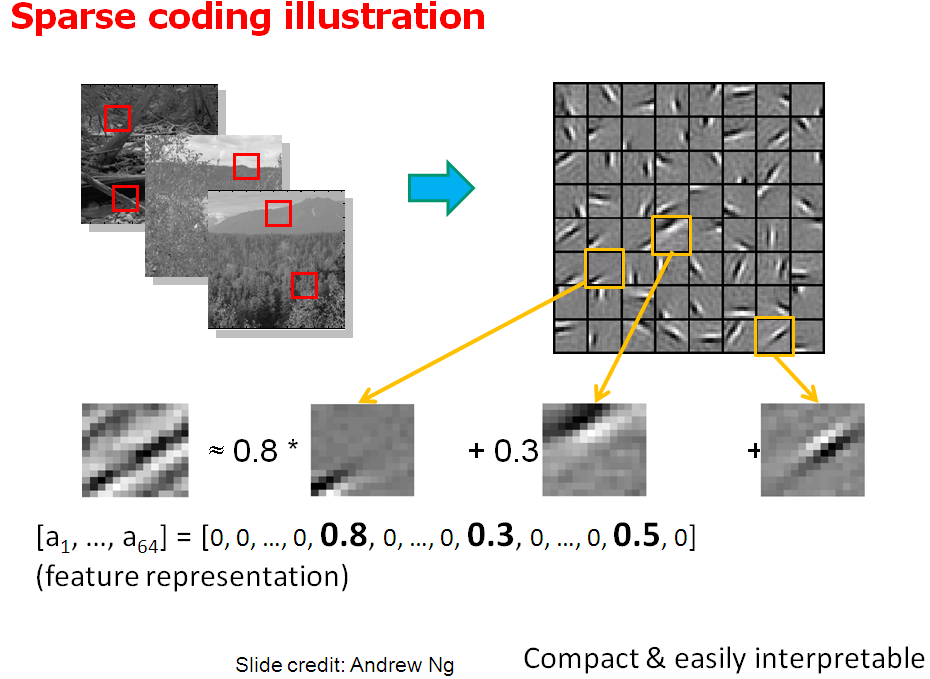
The sparse code is a kind of neural code in which each item is encoded by the strong activation of a relatively small set of neurons. For each item to be encoded, this is a different subset of all available neurons.
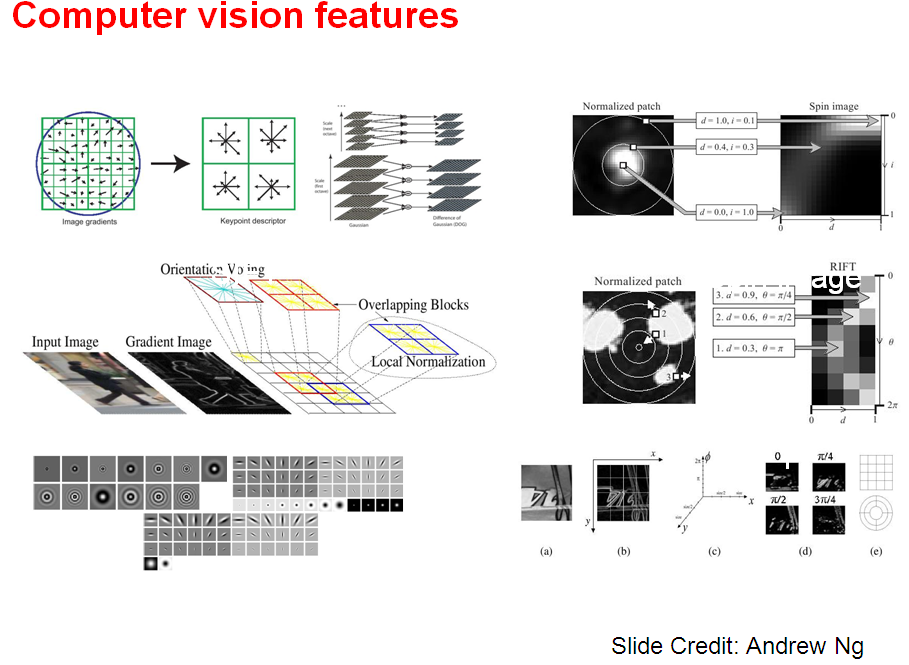
As a consequence, sparseness may be focused on temporal sparseness (“a relatively small number of time periods are active”) or on the sparseness in an activated population of neurons. In this latter case, this may be defined in one time period as the number of activated neurons relative to the total number of neurons in the population. This seems to be a hallmark of neural computations since compared to traditional computers, information is massively distributed across neurons. A major result in neural coding from Olshausen et al. is that sparse coding of natural images produces wavelet-like oriented filters that resemble the receptive fields of simple cells in the visual cortex.

Google hire Hinton who is an expert in Deep Learning.
Summary of Sparse Coding
* Sparse coding is an effect way for(unsupervised) feature learning
* A building block for deep models
* Sparse coding and its local variants (LCC, SVC) have pushed the boundary of accuracies on Caltech101, PASCAL VOC, ImageNet
* Challenge: discriminative training is not straightforward






Nextbigfuture covered an earlier article about Sparse Coding at Dwave
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.