

The work is based on a technique known as optogenetics, which uses proteins that change their function in response to light. In this case, the researchers adapted the light-sensitive proteins to either stimulate or suppress the expression of a specific target gene almost immediately after the light comes on.
“Cells have very dynamic gene expression happening on a fairly short timescale, but so far the methods that are used to perturb gene expression don’t even get close to those dynamics. To understand the functional impact of those gene-expression changes better, we have to be able to match the naturally occurring dynamics as closely as possible,” says Silvana Konermann, an MIT graduate student in brain and cognitive sciences.
The ability to precisely control the timing and duration of gene expression should make it much easier to figure out the roles of particular genes, especially those involved in learning and memory. The new system can also be used to study epigenetic modifications — chemical alterations of the proteins that surround DNA — which are also believed to play an important role in learning and memory.
2. CRISPR genome editing is being made more effective and accurate
Earlier this year, MIT researchers developed a way to easily and efficiently edit the genomes of living cells. Now, the researchers have discovered key factors that influence the accuracy of the system, an important step toward making it safer for potential use in humans, says Feng Zhang, leader of the research team.
With this technology, scientists can deliver or disrupt multiple genes at once, raising the possibility of treating human disease by targeting malfunctioning genes. To help with that process, Zhang’s team, led by graduate students Patrick Hsu and David Scott, has now created a computer model that can identify the best genetic sequences to target a given gene.
The genome-editing system, known as CRISPR, exploits a protein-RNA complex that bacteria use to defend themselves from infection. The complex includes short RNA sequences bound to an enzyme called Cas9, which slices DNA. These RNA sequences are designed to target specific locations in the genome; when they encounter a match, Cas9 cuts the DNA.
This approach can be used either to disrupt the function of a gene or to replace it with a new one. To replace the gene, the researchers must also add a DNA template for the new gene, which would be copied into the genome after the DNA is cut.
This technique offers a much faster and more efficient way to create transgenic mice, which are often used to study human disease. Current methods for creating such mice require adding small pieces of DNA to mouse embryonic cells. However, the process is inefficient and time-consuming.
With CRISPR, many genes are edited at once, and the entire process can be done in three weeks, says Zhang, who is a core member of the Broad Institute and MIT’s McGovern Institute for Brain Research. The system can also be used to create genetically modified cell lines for lab experiments much more efficiently.
Nature – DNA targeting specificity of RNA-guided Cas9 nucleases
Since Zhang and his colleagues first described the original system in January, more than 2,000 labs around the world have started using the system to generate their own genetically modified cell lines or animals. In the new paper, the researchers describe improvements in both the efficiency and accuracy of gene editing.
To modify genes using this system, an RNA “guide strand” complementary to a 20-base-pair sequence of targeted DNA is delivered to cells. After the RNA strand binds to the target DNA, it recruits the Cas9 enzyme, which snips the DNA in the correct location.
The researchers discovered they could minimize the chances of the Cas9-RNA complex accidentally cleaving the wrong site by making sure the target sequence is not too similar to other sequences found in the genome. They found that if an off-target sequence differs from the target sequence by three or fewer base pairs, the editing complex will likely also cleave that sequence, which could have deleterious effects for the cell.
The team’s new computer model can search any sequence within the mouse or human genome and identify 20-base-pair sequences within that region that have the least overlap with sequences elsewhere in the genome.
Another way to improve targeting specificity is by adjusting the dosage of the guide RNA, the researchers found. In general, decreasing the amount of RNA delivered minimizes damage to off-target sites but has a much smaller effect on cleavage of the target sequence. For each sequence, the “sweet spot” with the best balance of high on-target effects and low off-target effects can be calculated, Zhang says.
“The real value of this paper is that it does a very comprehensive and systematic analysis to understand the causes of off-target effects. That analysis suggests a lot of possible ways to eliminate or reduce off-target effects,” says Michael Terns, a professor of biochemistry and molecular biology at the University of Georgia who was not part of the research team.
Zhang and his colleagues also optimized the structure of the RNA guide needed for efficient activation of Cas9. In the January paper describing the original system, the researchers found that two separate RNA strands working together — one that binds to the target DNA and another that recruits Cas9 — produced better results than when those two strands were fused together before delivery. However, in experiments reported in the new paper, the researchers found that they could boost the efficiency of the fused RNA strand by making the strand longer. These longer RNA guide strands include a hairpin structure that may stabilize the molecules and help them interact with Cas9, Zhang says.
Zhang’s team is now working on further improving the specificity of the system, and plans to start generating cell lines and animals that could be used to study how the brain develops and builds neural circuits. By disrupting genes known to be involved in those processes, they can learn more about how they work and how they are impaired in neurological disease.
About CRISPR
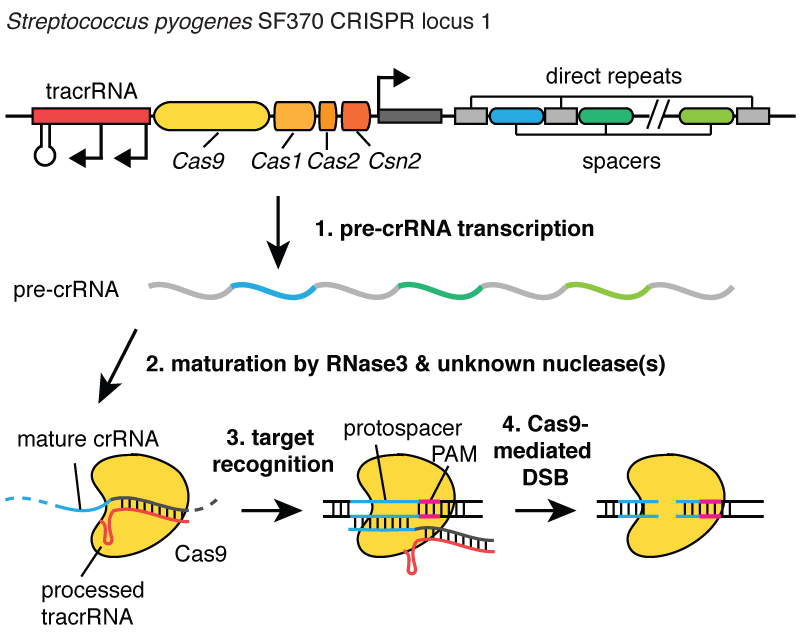
CRISPR is a microbial nuclease system involved in defense against invading phages and plasmids. CRISPR loci in microbial hosts contain a combination of CRISPR-associated (Cas) genes as well as non-coding RNA elements capable of programming the specificity of the CRISPR-mediated nucleic acid cleavage. Three types (I-III) of CRISPR systems have been identified across a wide range of bacterial hosts. One key feature of each CRISPR locus is the presence of an array of repetitive sequences (direct repeats) interspaced by short stretches of non-repetitive sequences (spacers). To license the associated Cas nuclease for nucleic acid cleavage, the non-coding CRISPR array is transcribed and cleaved within direct repeats into short crRNAs containing individual spacer sequences, which direct Cas nucleases to the target site (protospacer). The Type II CRISPR, shown below, is one of the most well characterized systems (see references) and carries out targeted DNA double-strand break in four sequential steps. First, two non-coding RNA, the pre-crRNA array and tracrRNA, are transcribed from the CRISPR locus. Second, tracrRNA hybridizes to the repeat regions of the pre-crRNA and mediates the processing of pre-crRNA into mature crRNAs containing individual spacer sequences. Third, the mature crRNA:tracrRNA complex directs Cas9 to the target DNA via Wastson-Crick base-pairing between the spacer on the crRNA and the protospacer on the target DNA next to the protospacer adjacent motif (PAM), an additional requirement for target recognition. Finally, Cas9 mediates cleavage of target DNA to create a double-stranded break within the protospacer.
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.