Stephen Hsu at Information Processing reports on a paper where the authors use machine learning techniques to build sparse predictors based on grey/white matter volumes of specific regions. Correlations obtained are ~ 0.7
A separate UCLA paper show that brain size alone correlates 0.4 with IQ. Also, a notable genetic sequence, located within the HMGA2 gene on chromosome 12, was linked with intracranial volume — in other words, the space inside your skull that marks the outer limit as to how big your brain can get.
PLOS One – MRI-Based Intelligence Quotient (IQ) Estimation with Sparse Learning
Abstract
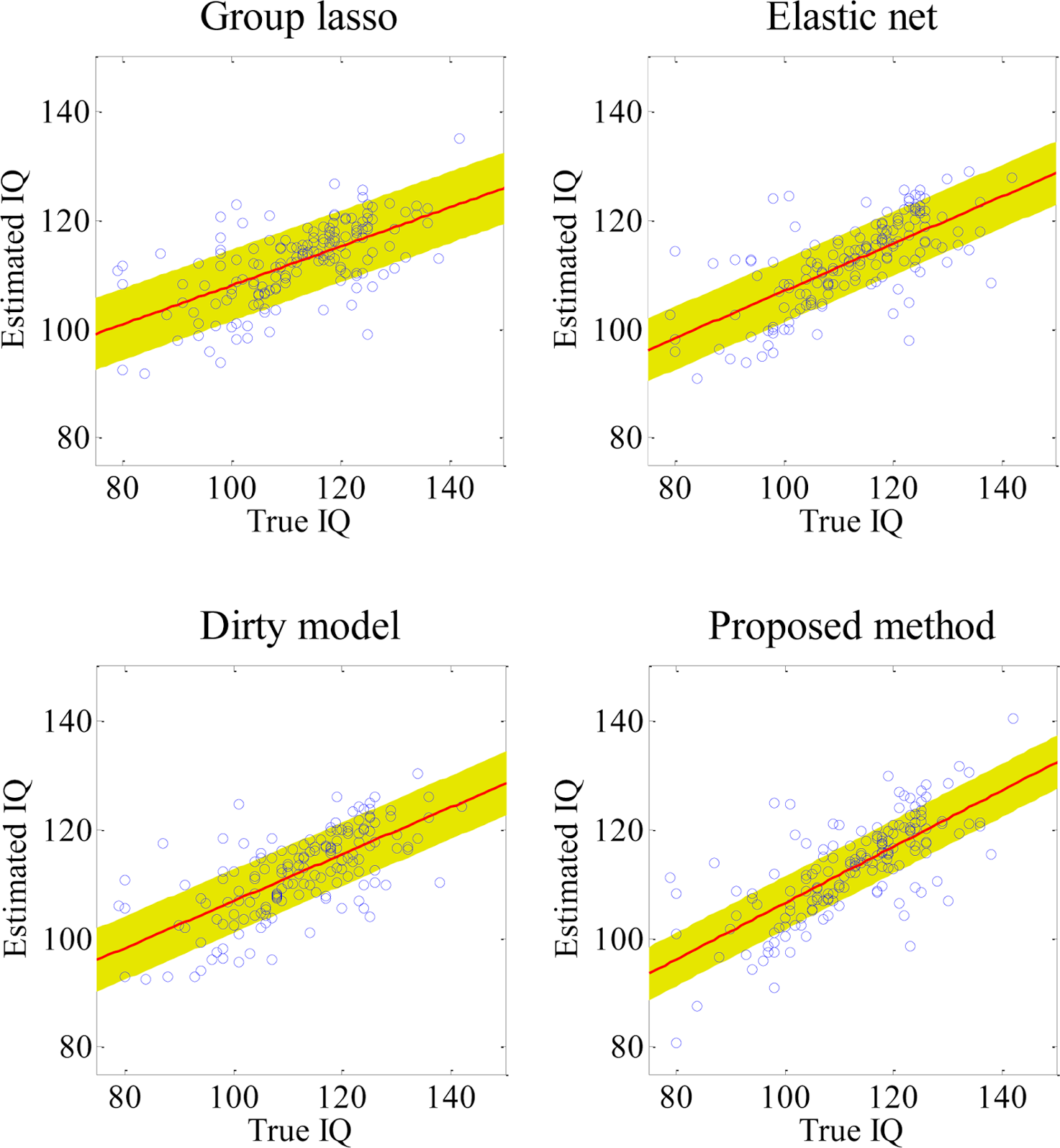
In this paper, we propose a novel framework for IQ estimation using Magnetic Resonance Imaging (MRI) data. In particular, we devise a new feature selection method based on an extended dirty model for jointly considering both element-wise sparsity and group-wise sparsity. Meanwhile, due to the absence of large dataset with consistent scanning protocols for the IQ estimation, we integrate multiple datasets scanned from different sites with different scanning parameters and protocols. In this way, there is large variability in these different datasets. To address this issue, we design a two-step procedure for 1) first identifying the possible scanning site for each testing subject and 2) then estimating the testing subject’s IQ by using a specific estimator designed for that scanning site. We perform two experiments to test the performance of our method by using the MRI data collected from 164 typically developing children between 6 and 15 years old. In the first experiment, we use a multi-kernel Support Vector Regression (SVR) for estimating IQ values, and obtain an average correlation coefficient of 0.718 and also an average root mean square error of 8.695 between the true IQs and the estimated ones. In the second experiment, we use a single-kernel SVR for IQ estimation, and achieve an average correlation coefficient of 0.684 and an average root mean square error of 9.166. All these results show the effectiveness of using imaging data for IQ prediction, which is rarely done in the field according to our knowledge.


The 15 most frequently selected brain areas by the proposed method.
Colors mainly show different regions. doi:10.1371/journal.pone.0117295.g005

Comparison of weight coefficient matrices for three different feature selection methods.
Each colored square corresponds to a non-zero element after feature selection. Circled squares (with the yellow ellipse outlines) correspond to the selected group-wise features, and circled squares (with black rectangle outlines) correspond to the selected pair-wise correlated features. (A) Group lasso. (B) Traditional dirty model. (C) The proposed extended dirty model. doi:10.1371/journal.pone.0117295.g002
Stephen Hsu wrote a paper which extrapolates the current intelligence and gene sequencing studies of height and intelligence to predict that once ~ 1 million genomes and cognitive scores are available for analysis we will have accurate genomic intelligence predictors.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.