

Nervana Systems ise building the first optimized, full-stack platform for machine intelligence. It will be built for ease of use, speed, and scale. Nervana’s brain-inspired deep learning solution abstracts away the complexities associated with AI development. They allow users to focus on building solutions that tackle the world’s toughest machine learning problems.
Nervana Systems has launched a deep learning cloud while it builds a chip designed for AI.
After two years of effort and more than $24 million in venture funding Nervana Systems has opened up its deep learning cloud so any business can build computer models that can learn.
They are building a specialized chip for deep learning.
Nervana’s cloud is based on graphics processors purchased from Nvidia, but the founders of Nervana hope to replace the underlying hardware by the end of 2016 with specialized chips of their own design. Until then, the founders have both re-engineered the firmware that the Nvidia chips use and built their own software framework so deep learning jobs run faster on their cloud.
Nervana Systems was founded by Naveen Rao, the former head of Qualcomm’s artificial intelligence chip efforts and two others who also left the mobile chip company to start Nervana.
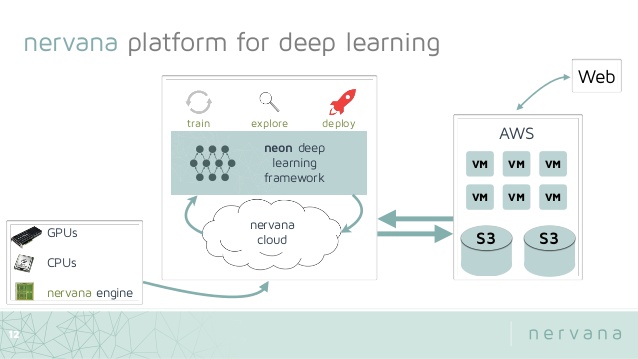
Nirvana’s Neon™ framework is open source and can be deployed on CPUs, GPUs or custom Nervana hardware. It supports all the commonly used models including convnets, MLPs, RNNs, LSTMs and autoencoders.
Why neon™?
• Fastest deep learning framework
• Easy to use Python-based framework
• Assembler level optimization for Maxwell GPUs
• Abstracts parallelism data caching and loading
• Support for different deep learning models
• Multiple backends (CPU, GPU, TX1, Nervana Engine)
• User-friendly and easily extensible
• Open source (Apache 2.0)
Deep learning thrives on speed. Faster training enables the construction of larger and more complex networks to tackle new domains such as speech or decision making.
Recently, small convolutional filter sizes have become an important component in convolutional neural networks such as Google’s AlphaGo network or Microsoft’s deep residual networks. While most convolutions are computed with the fast fourier transform (FFT) algorithm, the rising prominence of small 3×3 filter sizes makes the way for a lesser known technique specialized for small filter sizes: Winograd’s minimal filtering algorithms.
They have implemented the Winograd algorithm on GPUs and benchmarked performance and convergence on state-of-the-art networks. Depending on the network architecture, training with Nervana’s Winograd algorithm yields speed-ups of 2-3x over NVIDIA’s cuDNN v4 kernels.
Nervana Winograd is up to 3 times faster than Nvidia’s cuDNN v4

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.