

An AI has learned to read and answer questions about a news article with unprecedented accuracy. A group led by Stanford’s Chris Manning has designed an algorithm that beat DeepMind’s news understanding results by an impressive 10 per cent on the CNN articles and 8 per cent for Daily Mail stories. It scored 70 per cent overall.
The improvement came through streamlining the DeepMind model. “Some of the stuff they had just causes needless complications,” says Manning. “You get rid of that and the numbers go up.”
Google’s DeepMind team used articles from the Daily Mail website and CNN to help train an algorithm to read and understand a short story. The team used the bulleted summaries at the top of these articles to create simple interpretive questions that trained the algorithm to search for key points.
Arxiv – A Thorough Examination of the CNN / Daily Mail Reading Comprehension Task
Enabling a computer to understand a document so that it can answer comprehension questions is a central, yet unsolved goal of NLP. A key factor impeding its solution by machine learned systems is the limited availability of human-annotated data. Hermann et al seek to solve this problem by creating over a million training examples by pairing CNN and Daily Mail news articles with their summarized bullet points, and show that a neural network can then be trained to give good performance on this task. In this paper, we conduct a thorough examination of this new reading comprehension task. Our primary aim is to understand what depth of language understanding is required to do well on this task. Stanford researchers approached this from one side by doing a careful hand-analysis of a small subset of the problems and from the other by showing that simple, carefully designed systems can obtain accuracies of 72.4% and 75.8% on these two datasets, exceeding current state-of-the-art results by over 5% and approaching what we believe is the ceiling for performance on this task
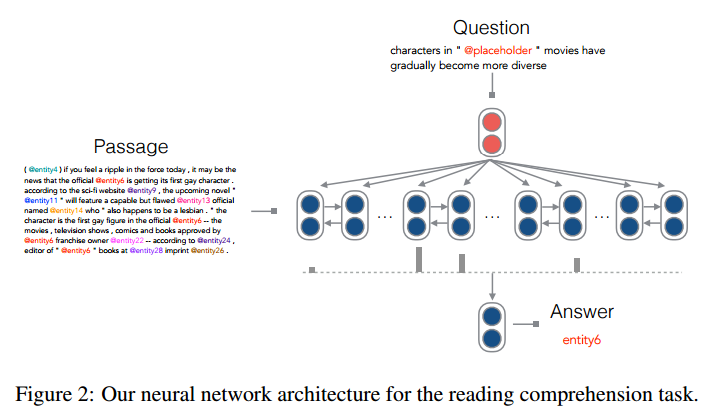
the Stanford model basically follows the Google Deepmind AttentiveReader. However, to their surprise, their experiments observed nearly 8–10% improvement over the original AttentiveReader results on CNN and Daily Mail datasets
Concretely, the Stanford model has the following differences:
1. Stanford uses a bilinear term, instead of a tanh layer to compute the relevance (attention) between question and contextual embeddings. The effectiveness
of the simple bilinear attention function has been shown previously for neural machine translation by (Luong et al., 2015).
2. After obtaining the weighted contextual embeddings o, they use o for direct prediction. In contrast, the original model in (Hermann et al., 2015) combined o and the question embedding q via another non-linear layer before making final predictions. Stanford found that they could remove this layer without harming performance. They believe it is sufficient for the model to learn to return the entity to which it maximally gives attention.
3. The original model considers all the words from the vocabulary V in making predictions. They think this is unnecessary, and only predict among entities which appear in the passage.
Of these changes, only the first seems important; the other two just aim at keeping the model simple
SOURCES – New Scientist, Arxiv

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.