

The announcement was made during a presentation by Greg Diamos and Sharan Narang of Baidu Research’s Silicon Valley AI Lab.
The primary purpose of DeepBench is to benchmark operations that are important to deep learning on different hardware platforms. Although the fundamental computations behind deep learning are well understood, the way they are used in practice can be surprisingly diverse. For example, a matrix multiplication may be compute-bound, bandwidth-bound, or occupancy-bound, based on the size of the matrices being multiplied and the kernel implementation. Because every deep learning model uses these operations with different parameters, the optimization space for hardware and software targeting deep learning is large and underspecified.
DeepBench attempts to answer the question, “Which hardware provides the best performance on the basic operations used for training deep neural networks?”. Baidu specify these operations at a low level, suitable for use in hardware simulators for groups building new processors targeted at deep learning.
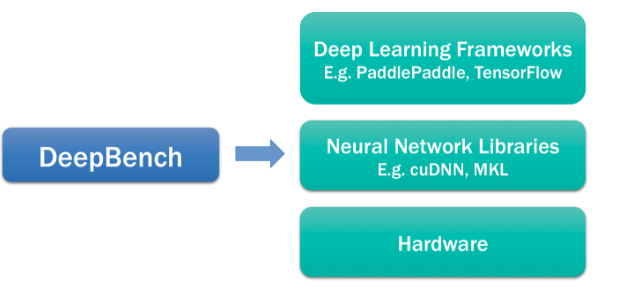
DeepBench uses the neural network libraries to benchmark the performance of basic operations on different hardware. It does not work with deep learning frameworks or deep learning models built for applications. We cannot measure the time required to train an entire model using DeepBench. The performance characteristics of models built for different applications are very different from each other. Therefore, we are benchmarking the underlying operations involved in training a deep learning model. Benchmarking these operations will help raise awareness amongst hardware vendors and software developers about the bottlenecks in deep learning training.
Types of Operations in Deep Bench
Dense Matrix Multiplies
Dense matrix multiplies exist in almost all deep neural networks today. They are used to implement fully connected layers and vanilla RNNs and are building blocks for other types of recurrent layers. Sometimes they are also used as a quick way to implement novel layer types for which custom code doesn’t exist.
Convolutions make up the vast majority of flops in networks that operate on images and videos and form important parts of networks such as speech and natural language modeling making them, perhaps, the single most important layer from a performance perspective.
Convolutions have 4 or 5 dimensional inputs and outputs giving rise to a large number of possible orderings for these dimensions. For the first version of the benchmark we are only concerned with performance in NCHW format i.e. data is presented in image, feature maps, rows and columns
Recurrent Layers
Recurrent layers are usually made up of some combination of the above operations and also simpler operations such as unary or binary operations which aren’t very compute intensive and generally are a small percentage of overall runtime. However, the GEMM and convolution operations are relatively small in recurrent layers, so the cost of these smaller operations can become significant. This is especially true if there is a high fixed overhead associated with starting a computation. It is also possible to use alternate storage formats for the recurrent matrices because the cost of converting to a new storage format can be amortized over the many steps of the recurrent computation. If this is done the time to convert to and from the custom format should be included in the overall time.
These factors lead to many optimization possibilities both within a time step and across a sequence of time steps such that measuring the raw performance of the operations is not necessarily representative of the performance of an entire recurrent layer. In this benchmark we focus on only one recurrent layer, even though there are even more optimization opportunities if one considers stacks of them.
All-Reduce
Neural networks are today often trained across multiple GPUs or even multiple systems each with multiple GPUs. There are two main categories of techniques for doing this: synchronous and asynchronous. Synchronous techniques rely on keeping the parameters on all instances of the model synchronized, usually by making sure all instances of the model have the same copy of the gradients before taking an optimization step. The Message Passing Interface (MPI) primitive usually used to perform this operation is called All-Reduce. There are many ways to implement All-Reduce based on the number of ranks, the size of the data, and the topology of the network. This benchmark places no constraints on the implementation other than that it should be deterministic. Asynchronous methods are quite varied and in this version of the benchmark we will not be attempting to test these methods.
SOURCES- Baidu Research, Forbes, Github

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.