

Artificial intelligence is getting its teeth into lip reading. A project by Google’s DeepMind and the University of Oxford applied deep learning to a huge data set of BBC programmes to create a lip-reading system that leaves professionals in the dust.
The AI system was trained using some 5000 hours from six different TV programmes, including Newsnight, BBC Breakfast and Question Time. In total, the videos contained 118,000 sentences.
The AI vastly outperformed a professional lip-reader who attempted to decipher 200 randomly selected clips from the data set.
The professional annotated just 12.4 per cent of words without any error. But the AI annotated 46.8 per cent of all words in the March to September data set without any error. And many of its mistakes were small slips, like missing an ‘s’ at the end of a word. With these results, the system also outperforms all other automatic lip-reading systems.
“It’s a big step for developing fully automatic lip-reading systems,” says Ziheng Zhou at the University of Oulu in Finland. “Without that huge data set, it’s very difficult for us to verify new technologies like deep learning.”
Two weeks ago, a similar deep learning system called LipNet – also developed at the University of Oxford – outperformed humans on a lip-reading data set known as GRID. But where GRID only contains a vocabulary of 51 unique words, the BBC data set contains nearly 17,500 unique words, making it a much bigger challenge.

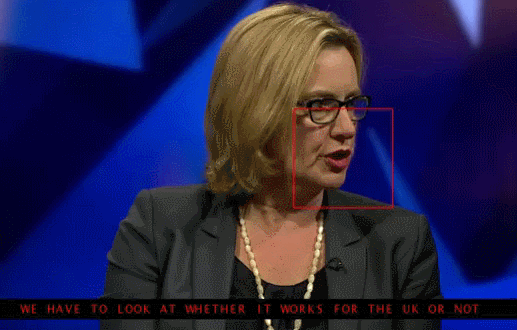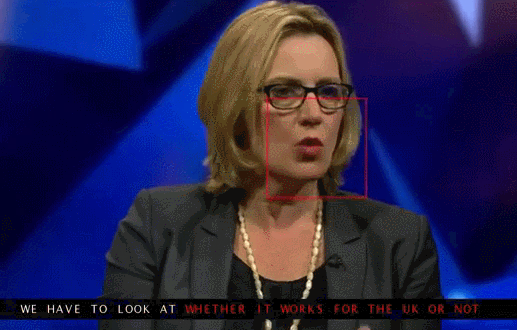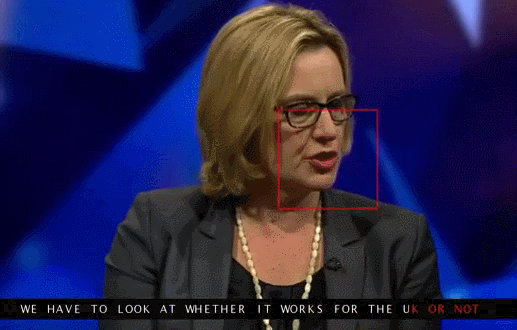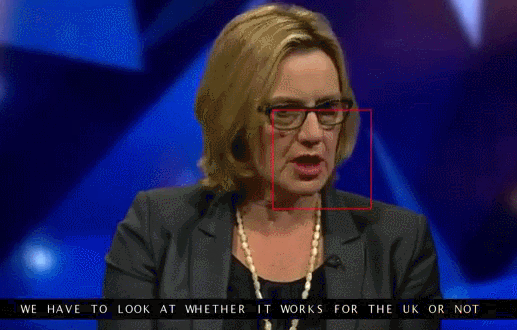
Arxiv – Lip Reading Sentences in the Wild
Abstract
The goal of this work is to recognize phrases and sentences being spoken by a talking face, with or without the audio. Unlike previous works that have focussed on recognizing a limited number of words or phrases, we tackle lip reading as an open-world problem – unconstrained natural language sentences, and in the wild videos.
Our key contributions are:
(1) a ‘Watch, Listen, Attend and Spell’ (WLAS) network that learns to transcribe videos of mouth motion to characters;
(2) a curriculum learning strategy to accelerate training and to reduce overfitting;
(3) a ‘Lip Reading Sentences’ (LRS) dataset for visual speech recognition, consisting of over 100,000 natural sentences from British television.
The WLAS model trained on the LRS dataset surpasses the performance of all previous work on standard lip reading benchmark datasets, often by a significant margin. This lip reading performance beats a professional lip reader on videos from BBC television, and we also demonstrate that visual information helps to improve speech recognition performance even when the audio is available.
SOURCES- Arxiv, Youtube, New Scientist, Google, Deep Mind

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Kudüs’ün Tarihçesi ve Dinî Ehemmiyeti