
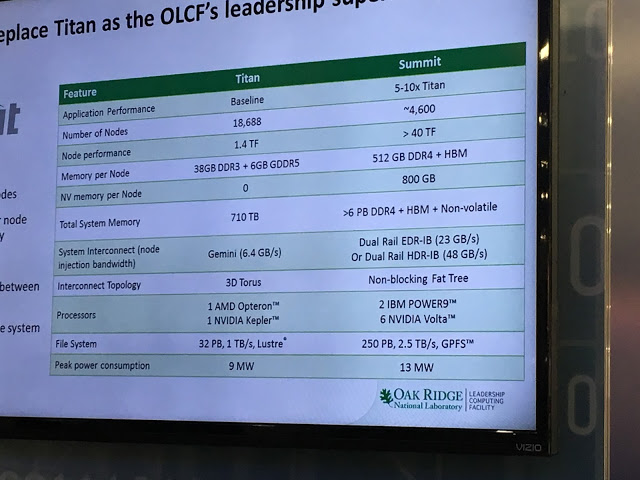
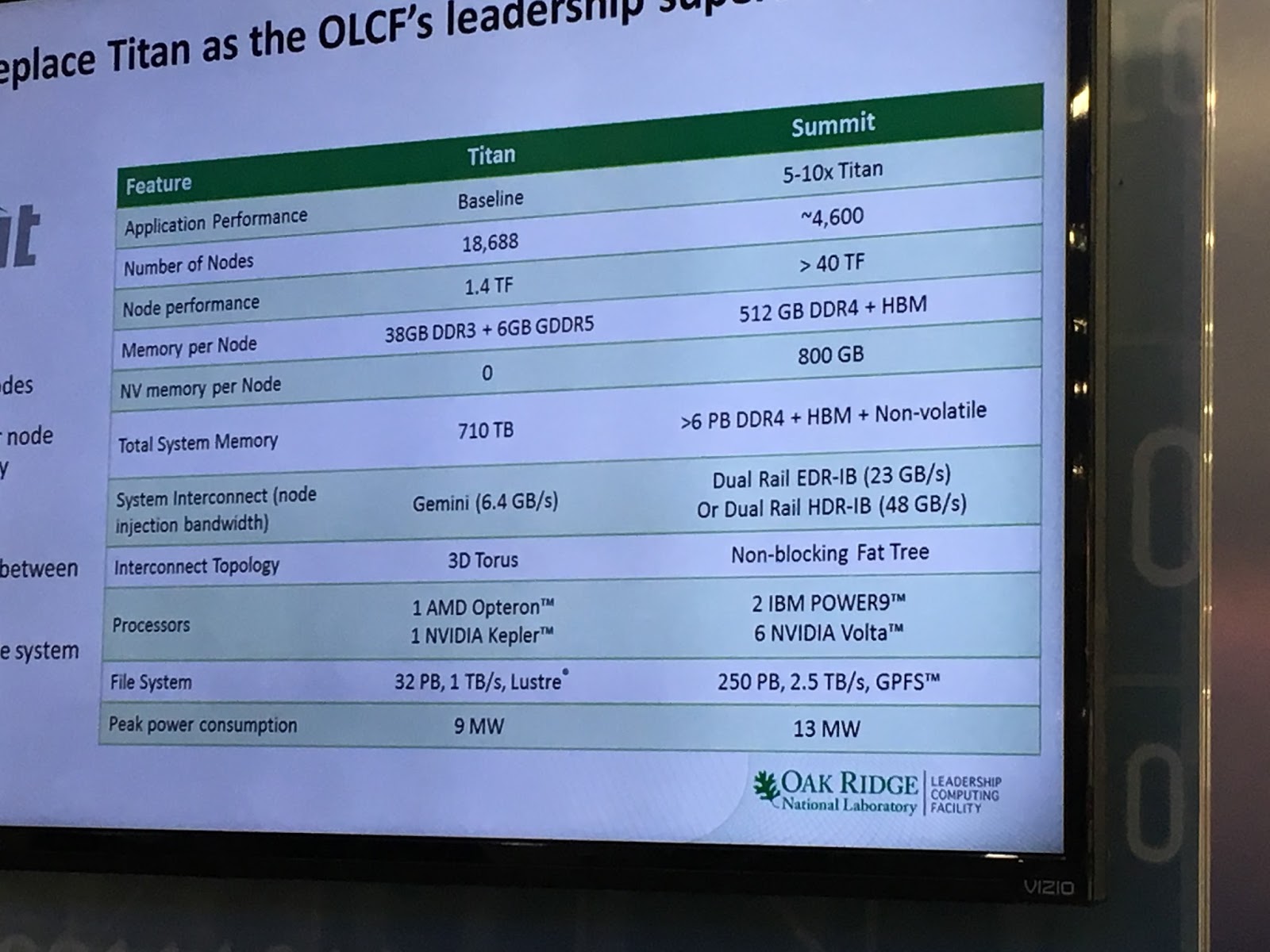
The future “Summit” pre-exascale supercomputer that is being built out in late 2017 and early 2018 for the US Department of Energy for its Oak Ridge National Laboratory looks like a giant cluster of systems that might be used for training neural networks. And that is an extremely convenient development.
More than once during the SC16 supercomputing conference this week in Salt Lake City, the Summit system and its companion “Sierra” system that will be deployed at Lawrence Livermore National Laboratory, were referred to as “AI supercomputers.” This is a reflection of the fact that the national labs around the world are being asked to do machine learning on the same machines that would normally just do simulation and modeling to advance science, not just to advance the art of computation but to make these systems all look more cool and more useful. With pre-exascale machines costing hundreds of millions of dollars, it is important to get the most use out of them as possible.
The most powerful supercomputer, a relatively new Chinese supercomputer named Sunway TaihuLight, is capable of 93 petaflops. It is built entirely using processors designed and made in China. In June, it displaced Tianhe-2, an Intel-based Chinese supercomputer that had claimed the number one spot on the six previous TOP500 lists.
Tianhe-2, the number two system, achieved a speed of 33.86 petaflops, or more than 33,000 trillion calculations per second, in a test known as the LINPACK benchmark. That ranking program uses a series of linear equations to test computer systems around the world.
Titan (25 petaflop), the number three system, was the top supercomputer for a short time. It was number one in November 2012, but it was bumped to number two behind Tianhe-2 in June 2013. This past June was the first time it had been number three.
As big as a basketball court, Titan is 10 times faster than Jaguar, the computer system it replaced. Jaguar, which was capable of about 2.5 petaflops, had ranked as the world’s fastest computer in November 2009 and June 2010.
IBM and Nvidia are under pressure to make the Summit machine more powerful, and is cramming more GPUs in the nodes and scaling up the number of nodes to make it happen. At 43.5 teraflops peak, the Summit machine at 4,600 nodes would break through 200 petaflops of peak theoretical performance, which would probably put IBM at the top of the Top 500 supercomputer rankings in November 2017 if the machine can be up and running with Linpack by then. This 200 petaflops number is a psychological barrier, not a technical one, but in a Trump Administration, it might be a very important psychological barrier indeed. (China is winning the Petaflops War.)

At 50 teraflops of performance per node (doable if the feeds and speeds for Volta work out), that is a 230 petaflops cluster peak, and if the performance of the Volta GPUs can be pushed to an aggregate of 54.5 teraflops, then we are talking about crossing through 250 petaflops – a quarter of the way to exascale. And this is also a massive machine that could, in theory, run 4,600 neural network training runs side-by-side for machine learning workloads (we are not saying it will), but at the half precision math used in machine learning, that is above an exaflops of aggregate compute capacity.
SOURCES – Nextplatform, nvidia, oak ridge national lab

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.