

Deep learning has continued to drive the computing industry’s agenda in 2016. But come 2017, experts say the Artificial Intelligence community will intensify its demand for higher performance and more power efficient “inference” engines for deep neural networks.
The current deep learning system leverages advances in large computation power to define network, big data sets for training, and access to the large computing system to accomplish its goal.
Unfortunately, the efficient execution of this learning is not so easy on embedded systems (i.e. cars, drones and Internet of Things devices) whose processing power, memory size and bandwidth are usually limited.
This problem leaves wide open the possibility for innovation of technologies that can put deep neural network power into end devices.
“Deploying Artificial Intelligence at the edge [of the network] is becoming a massive trend,” Movidius CEO, Remi El-Ouazzane, told us a few months ago.
Semiconductor suppliers like Movidus (armed with Myriad 2), Mobileye (EyeQ 4 & 5) and Nvidia (Drive PX) are racing to develop ultra-low power, higher performance hardware-accelerators that can execute learning better on embedded systems.
Their SoC work illustrates that inference engines are already becoming “a new target” for many semiconductor companies in the post-mobile era, observed Duranton.
Google’s Tensor Processing Units (TPUs) unveiled earlier this year marked a turning point for an engineering community eager for innovations in machine learning chips.
At the time of the announcement, the search giant described TPUs as offering “an order of magnitude higher performance per Watt than commercial FPGAs and GPUs.” Google revealed that the accelerators were used for the AlphaGo system, which beat a human Go champion. However, Google has never discussed the details of TPU architecture, and the company won’t be selling TPUs on the commercial market.
Many SoC designers view that Google’s move made the case that machine learning needs custom architecture
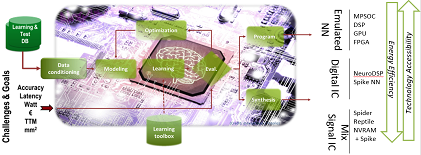
CEA is offering an ultra-low power programmable accelerator, called P-Neuro.
Compared to the embedded GPU (Tegra K1), P-Neuro based on FPGA running at 100MHz has proven to be faster by a factor of two, and four to five times more energy efficient.
P-Neuro is built on clustered SIMD architecture, featuring optimized memory hierarchy and interconnect

An EU project, called NeuRAM3, says its chip will feature “an ultra-low power, scalable and highly configurable neural architecture.” The goal is to deliver “a gain of a factor 50x in power consumption on selected applications compared to conventional digital solutions.”
SOURCE – EETimes

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.