

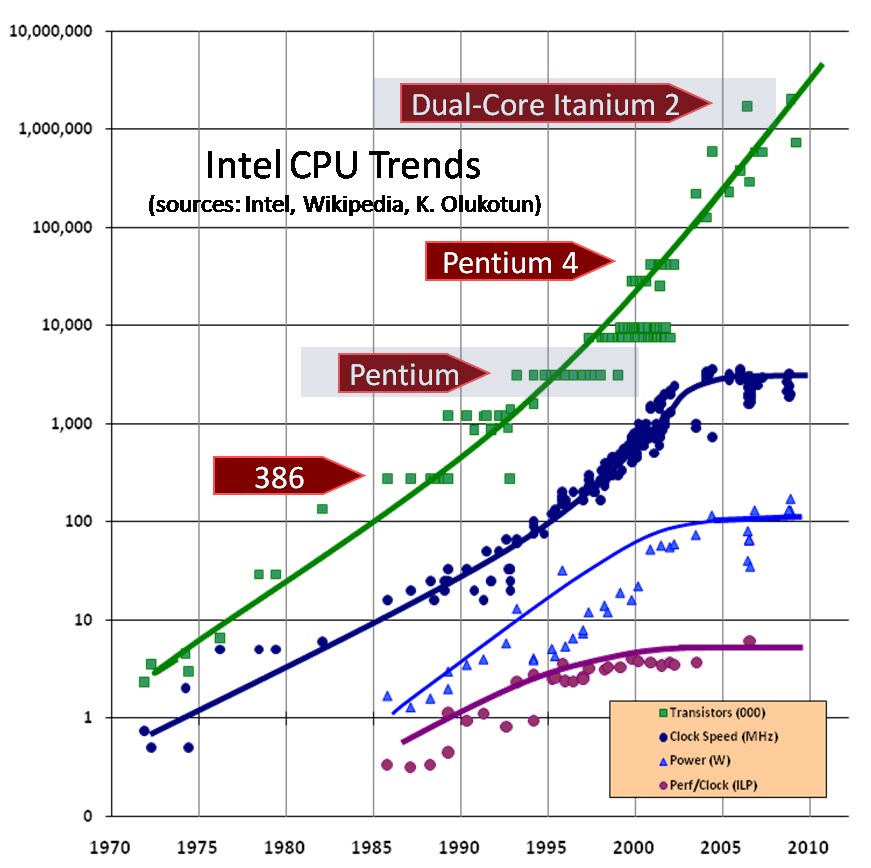
CPUs vastly slowed in performance scaling around 1997-2004.
You can see it with the lines showing flat clock speeds and performance per clock. However, you already knew it from the lack of real performance improvement in laptops and desktop computers.
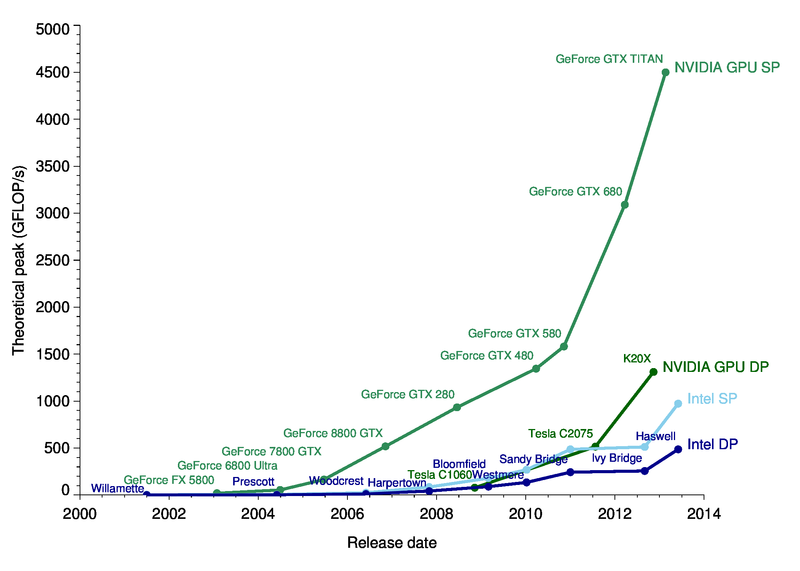
GPUs kept to Moore’s law in terms of performance improvement.
Google went beyond Moore’s law performance improvement by using custom ASICs
Google Tensor flow processors are on average 15x to 30x faster in executing Google’s regular machine learning workloads than a standard GPU/CPU combination (Intel Haswell processors and Nvidia K80 GPUs). The TPUs also offer 30x to 80x higher TeraOps/Watt (and with using faster memory in the future, those numbers will probably increase).
Google says it started looking into how it could use GPUs, FPGAs and custom ASICS (which is essentially what the TPUs are) in its data centers back in 2006.
For compute heavy applications and businesses, custom ASICS (or minimally GPUs) are needed to be competitive.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.