
Together with EPFL scientists, our IBM Research team has developed a scheme for training big data sets quickly. It can process a 30 Gigabyte training dataset in less than one minute using a single graphics processing unit (GPU) — a 10x speedup over existing methods for limited memory training. The results, which efficiently utilize the full potential of the GPU, are being presented at the 2017 NIPS Conference in Long Beach, California.
Training a machine learning model on a terabyte-scale dataset is a common, difficult problem. If you’re lucky, you may have a server with enough memory to fit all of the data, but the training will still take a very long time. This may be a matter of a few hours, a few days or even weeks.
Specialized hardware devices such as GPUs have been gaining traction in many fields for accelerating compute-intensive workloads, but it’s difficult to extend this to very data-intensive workloads.
In order to take advantage of the massive compute power of GPUs, we need to store the data inside the GPU memory in order to access and process it. However, GPUs have a limited memory capacity (currently up to 16GB) so this is not practical for very large data.
One straightforward solution to this problem is to sequentially process the data on the GPU in batches. They partition the data into 16GB chunks and load these chunks into the GPU memory sequentially.
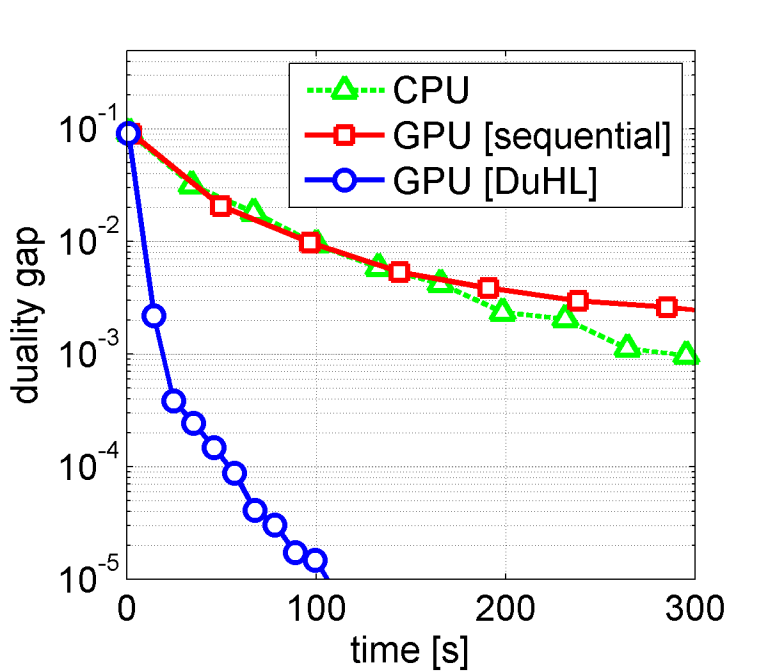
They set out to create a technique that determines which smaller part of the data is most important to the training algorithm at any given time. For most datasets of interest, the importance of each data-point to the training algorithm is highly non-uniform, and also changes during the training process. By processing the data-points in the right order the model can learn more quickly.
They call it DuHL for Duality-gap based Heterogeneous Learning. In addition to an application involving GPUs, the scheme can be applied to other limited memory accelerators (e.g. systems that use FPGAs instead of GPUs) and has many applications, including large data sets from social media and online marketing, which can be used to predict which ads to show users. Additional applications include finding patterns in telecom data and for fraud detection.
The new approach using DuHL achieves a 10x speed-up over the CPU.
Arxiv – Efficient Use of Limited-Memory Accelerators for Linear Learning on Heterogeneous Systems
They propose a generic algorithmic building block to accelerate training of machine learning models on heterogeneous compute systems. The scheme allows to efficiently employ compute accelerators such as GPUs and FPGAs for the training of large-scale machine learning models, when the training data exceeds their memory capacity. Also, it provides adaptivity to any system’s memory hierarchy in terms of size and processing speed. They technique is built upon novel theoretical insights regarding primal-dual coordinate methods, and uses duality gap information to dynamically decide which part of the data should be made available for fast processing. To illustrate the power of our approach we demonstrate its performance for training of generalized linear models on a large-scale dataset exceeding the memory size of a modern GPU, showing an order-of-magnitude speedup over existing approaches.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.