

OpenAI CEO Sam Altman was interviewed about GPT4 and other AI topics at a conference one year ago.
GPT-4 is coming, but currently the focus is on coding and that’s also where the available compute is going. GPT-4 will be a text model (as opposed to multi-modal). It will not be much bigger than GPT-3, but it will use way more compute. People will be surprised how much better you can make models without making them bigger.
GPT4 should have 20X GPT3 compute. GPT4 should have 10X parameters. GPT 5 should have 10X-20X of GPT4 compute in 2025. GPT5 will have 200-400X compute of GPT3 and 100X parameters of GPT3.
The progress will come from OpenAI working on all aspects of GPT (data, algos, fine-tuning, etc.). GPT-4 will likely be able to work with longer context and be trained with a different loss function – OpenAI has “line of sight” for this.
GPT-5 might be able to pass the Turing test. But this will probably not be worth the effort.
GPT-4 will likely be released in the second half of 2023. GPT-5 should be expected at the end of 2024 or in 2025.
100 trillion parameter model won’t be GPT-4 and is far off. They are getting much more performance out of smaller models. Maybe they will never need such a big model.
Less Wrong reviewed the GPT-4 predictions including information from Matthew Barnett.
There's been a lot of low-quality GPT-4 speculation recently. So, here's a relatively informed GPT-4 speculation thread from an outsider who still doesn't know that much. 🧵
— Matthew Barnett (@MatthewJBar) December 20, 2022
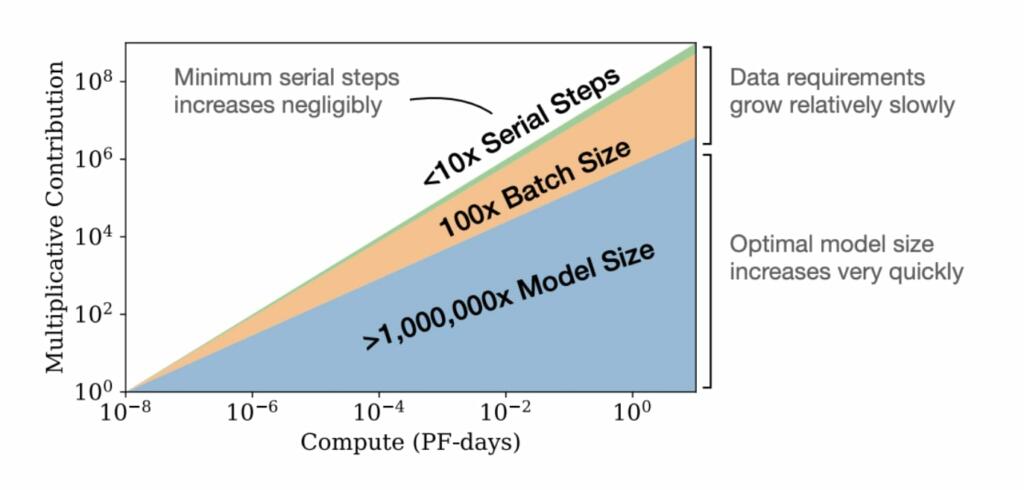
According to the paper Scaling Laws for Neural Language Models (2020), model performance as measured by cross-entropy loss can be calculated from three factors: the number of parameters in the model, the amount of compute used during training, and the amount of training data. There is a power-law relationship between these three factors and the loss. Basically, this means you have to increase the amount of compute, data, and parameters by a factor of 10 to decrease the loss by one unit, by 100 to decrease the loss by two units, and so on. The authors of the paper recommended training very large models on relatively small amounts of data and recommended investing compute into more parameters over more training steps or data to minimize loss.
For every 10x increase in compute, the paper approximately recommends increasing the number of parameters by 5x, the number of training tokens by 2x, and the number of serial training steps by 1.2x.
In May 2020 (around the release date of GPT-3), Microsoft announced that it created a new AI training supercomputer exclusively for OpenAI. The supercomputer had about 285,000 CPUs and 10,000 GPUs and it ranked in the top 5 supercomputers in the world. Assuming that it used a similar architecture to Nvidia’s Selene supercomputer (A100s), then it would have 1250 DGX A100 nodes which are equivalent to about 9 DXB SuperPODs.
In March 2022, Nvidia announced a new supercomputer named Eos which uses 4608 H100 GPUs and was expected to begin operating in late 2022 though I’m not sure if it’s actually been built yet. Assuming that each H100 is 4x faster than an A100 GPU, then Eos should have a performance of about 3 EFLOP/s.
If GPT-4’s compute budget is 5.63e24 FLOP, these scaling laws suggest that GPT-4 will be similar in size to GPT-3 to achieve optimal loss. A compute budget of 5.63e24 should have between about 175B and 280B parameters.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Scaling Laws for FEED-FORWARD Language Models (2020)
Everyone is barking up the wrong tree. Language statistics are fine and dandy as a first stop on the way to language dynamics but people are kidding themselves if they think this is going to end well if it ends with language statistics. Physics got stuck at the statics level from the time of Aristotle until Newton et al.
Moreover, even in the land of statistics, there are these things known as “information criteria for model selection” that tell us that whatever we’re doing to avoid over-fitting, it isn’t principled and that we should, at this stage, be far more interested in parameter distillation to figure out what the hell is going on than in just throwing more hardware at the problem.
The place to put money at this point is The Hutter Prize for Lossless Compression of Human Knowledge because each incremental invetment of money is guaranteed to bring improvement in the meta-science of modeling, which is where our real ignorance is.
ChatGPT “knows”, implicitly, it has this kind of limitation, as evidenced by the following response. If you don’t understand my point about “FEED-FORWARD”, then ask yourself why all of the current “large” language models have an inherent limit on the length of a response to a prompt. Reality is dynamic and an adequate model of reality must be dynamic — hence have FEED-BACK — carrying the current state into the next state ad infinitum.
James Bowery:
what is the longest response that a GPT3.5 language model can make to a prompt?
ChatGPT:
As an AI language model, GPT-3.5 can generate responses of varying lengths depending on the complexity of the prompt and the desired output length. The maximum response length in GPT-3.5 is 2048 tokens, which includes words, punctuation marks, and spaces.
However, in practice, the length of the response may be limited by the computational resources available and the constraints imposed by the platform or application using the model. Some platforms or applications may limit the response length to a smaller number of tokens to avoid overwhelming the user or to meet specific requirements.
In general, GPT-3.5 can generate responses of considerable length, but the actual response length may vary depending on the specific use case and the available computational resources.