

Cerebras open sources seven GPT-3 models from 111 million to 13 billion parameters. Trained using the Chinchilla formula, these models set new benchmarks for accuracy and compute efficiency. Cerebras makes wafer scale computer chips.
Cerebras-GPT has faster training times, lower training costs, and consumes less energy than any publicly available model to date.
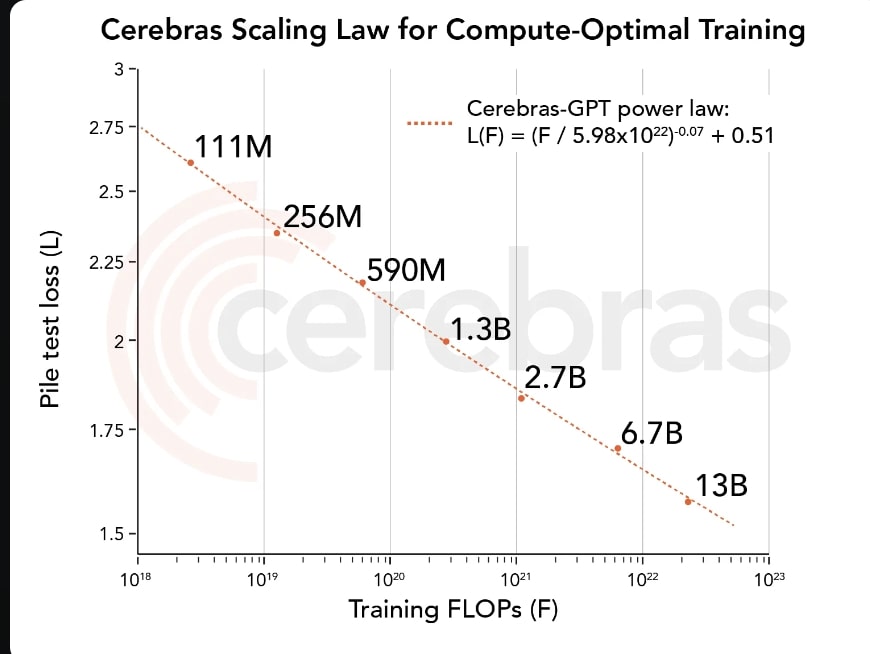

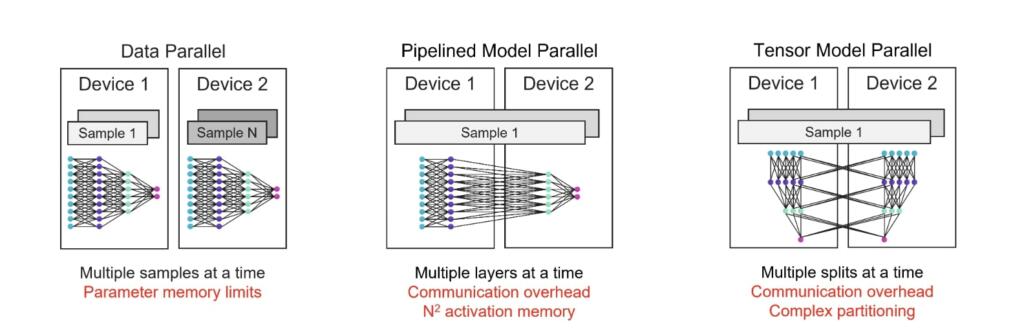
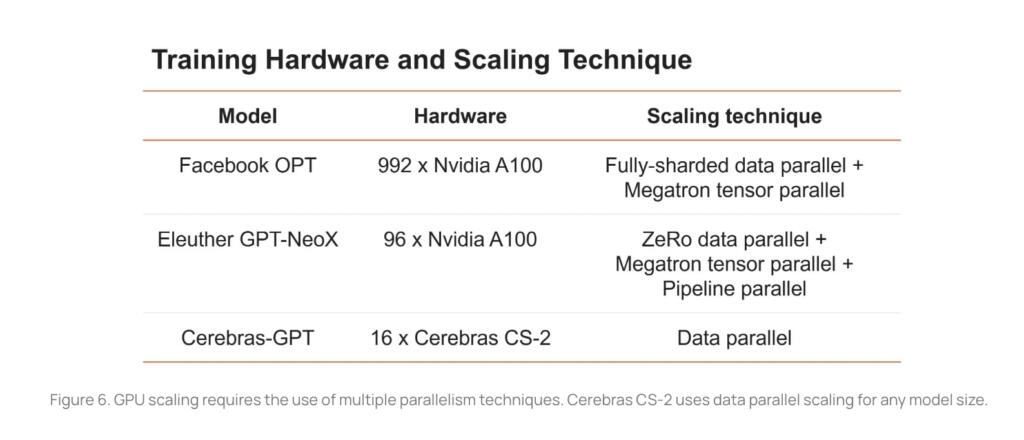
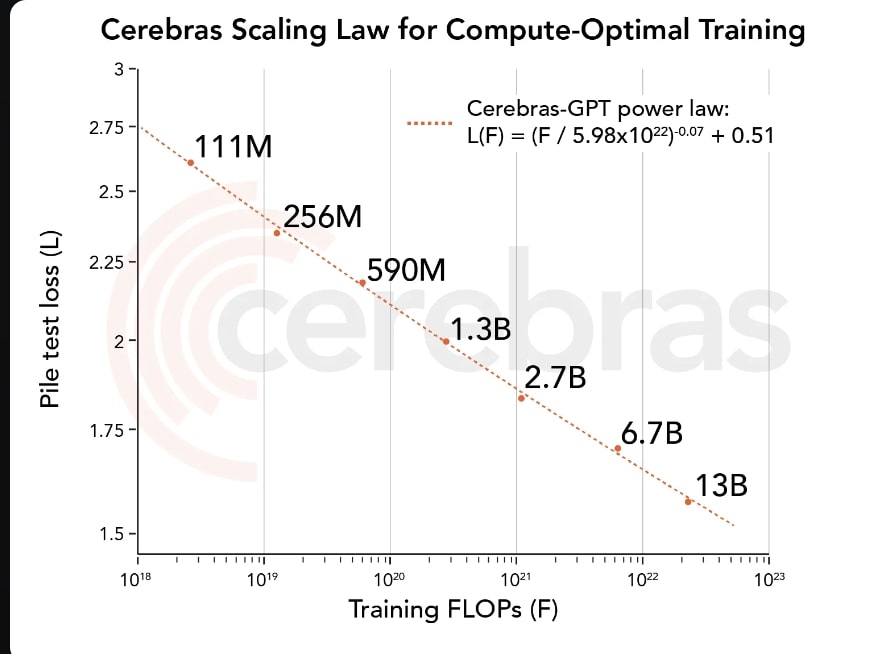
All models were trained on CS-2 systems that are part of the Andromeda AI supercomputer using our simple, data-parallel weight streaming architecture. By not having to worry about model partitioning, we were able to train these models in just a few weeks. Training these seven models has allowed us to derive a new scaling law. Scaling laws predict model accuracy based on the training compute budget and have been hugely influential in guiding AI research. To the best of our knowledge, Cerebras-GPT is the first scaling law that predicts model performance for a public dataset.
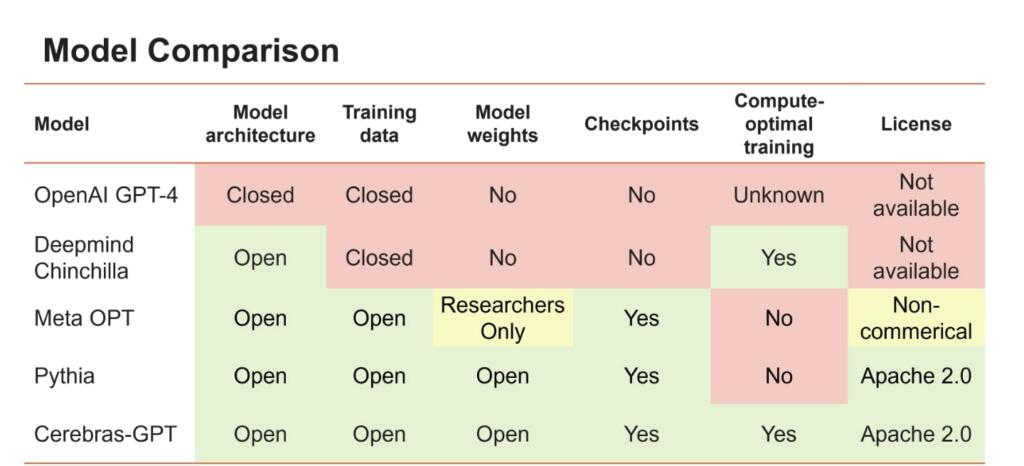
Today’s release is designed to be used by and reproducible by anyone. All models, weights, and checkpoints are available on Hugging Face and GitHub under the Apache 2.0 license. Additionally, we provide detailed information on our training methods and performance results in our forthcoming paper. The Cerebras CS-2 systems used for training are also available on-demand via Cerebras Model Studio.


Cerebras-GPT: A New Model For Open LLM Development
Artificial intelligence has the potential to transform the world economy, but its access is increasingly gated. The latest large language model – OpenAI’s GPT4 – was released with no information on its model architecture, training data, training hardware, or hyperparameters. Companies are increasingly building large models using closed datasets and offering model outputs only via API access.
For LLMs to be an open and accessible technology, we believe it’s important to have access to state-of-the-art models that are open, reproducible, and royalty free for both research and commercial applications. To that end, we have trained a family of transformer models using the latest techniques and open datasets that we call Cerebras-GPT. These models are the first family of GPT models trained using the Chinchilla formula and released via the Apache 2.0 license.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Any news on analog computing advances, with regard to AI? Digital computer based AI training is still taking enormous resources.
Kind of ironic that this closed release of GPT4 is a product of Open AI which was created and named that for exactly this reason.
Time to slow it down a bit?
“Elon Musk, along with a number of tech executives and experts in AI, computer science and other disciplines, in an open letter published Tuesday urged leading artificial intelligence labs to pause development of AI systems more advanced than GPT-4, citing “profound risks” to human society.
The open letter, issued by the nonprofit Future of Life Institute, counts more than 1,000 signatories, including Musk, Apple co-founder Steve Wozniak, Stability AI CEO Emad Mostaque and Sapiens author Yuval Noah Harari. It calls for an immediate halt in training of systems for at least six months, which must be public, verifiable and include all public actors.”
See:
https://www.cnet.com/tech/elon-musk-urges-top-ai-labs-to-pause-training-of-ai-beyond-gpt-4/