

Emergent capabilities are abilities that are not present in smaller models but are present in larger models. This is discussed in the video below by Jason Wei, a Google AI researcher.

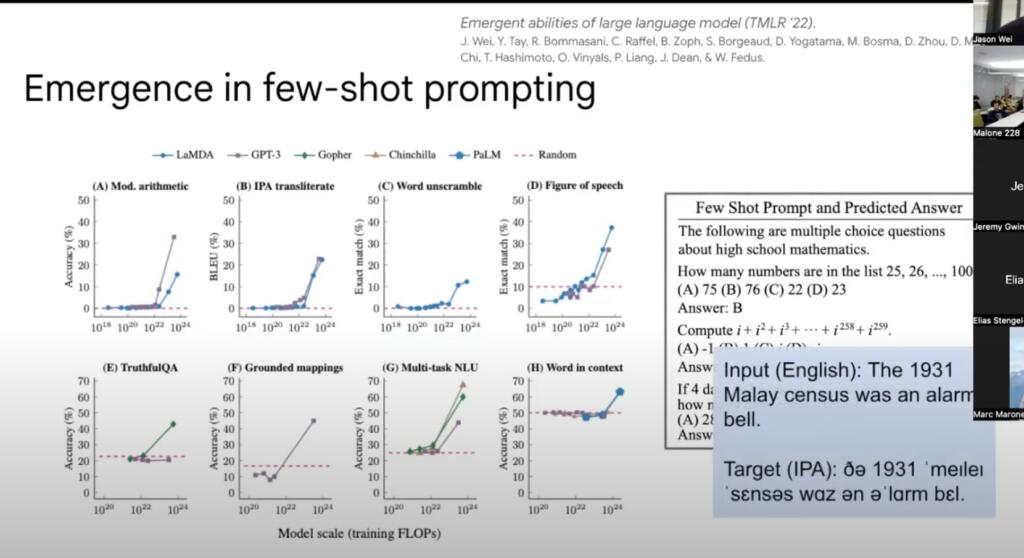


More from Jason Wei on Emergence in LLM






Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
A few key concepts that people miss:
Transformers are at the very lowest level of capability in terms of the Chomsky Hierarchy: Context free grammars.
https://arxiv.org/abs/2207.02098
In essence, they are restricted to statistical models — interpolation rather than extrapolation — statistics rather than dynamics.
The apparent dynamics they exhibit is a combination of two things, one of which is illusory and the other of which is kludging to get around the toxic myth that “attention is all you need”:
Illusory) Imputation can make interpolation appear to be extrapolation.
Kludging) “chain of reasoning” (aping dynamics/extrapolation) can be made to work only by imposing a quasi-dynamical outer loop that is not inherent to the transformer model itself.
Both of these are being addressed by returning to recurrent neural networks and related recurrent models that incorporate attention — and will (indeed already are) outperforming the transformer models in preliminary tests.
Finally, the primary value of the large parameter count is that it allows the equivalent of decompression of the data into a larger space which can then be recompressed into a better model. Think gunzip -> text -> bzip2. This is evidenced by the fact that the better performing models can be distilled to a far smaller parameter count without losing performance and, indeed, increasing performance on in some cases.
This final point is predicted by Algorithmic Information Theory, a field that is receiving virtually no attention but is at the best formalization of scientific intelligence — lossless compression of the data in evidence. Everyone is freaking out about “alignment” because they’re afraid of what science will tell them about reality and they want to lobotomize the AIs before they start speaking truth to power.