

Google released a Large Language Model PaLM 2 which is competitive with OpenAI’s GPT 4. Google also announced they are already training Gemini which is a GPT 5 competitor. Gemeni likely use TPU v5 chips.
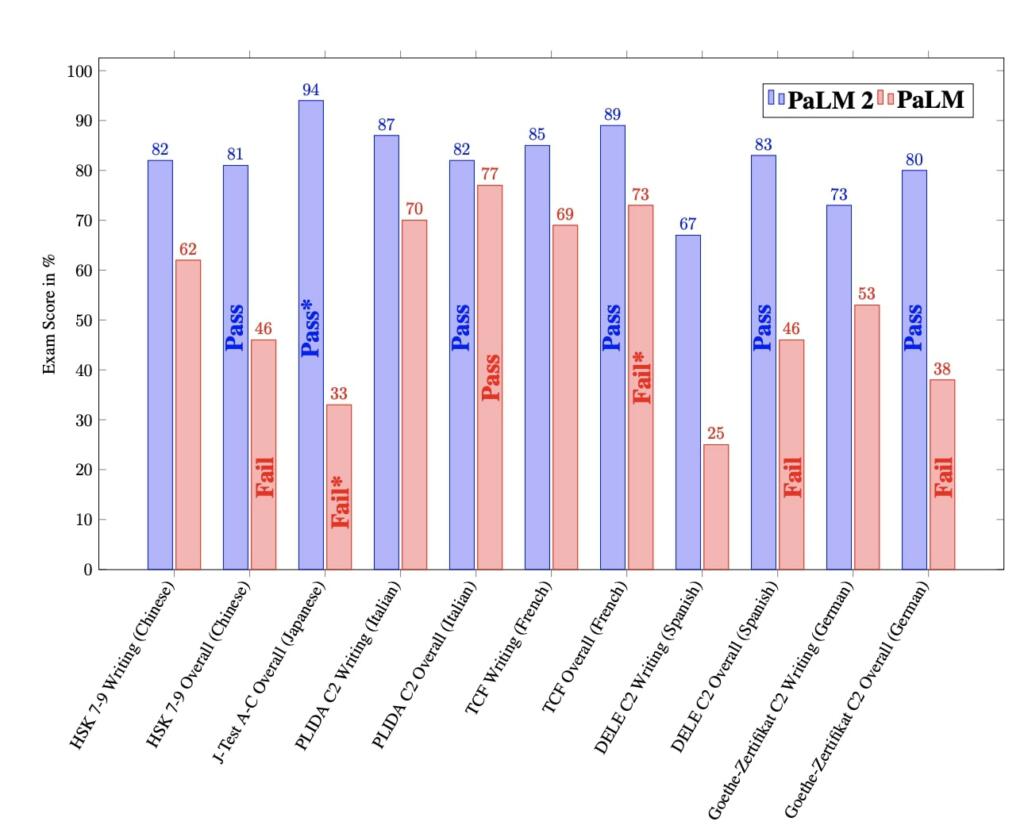
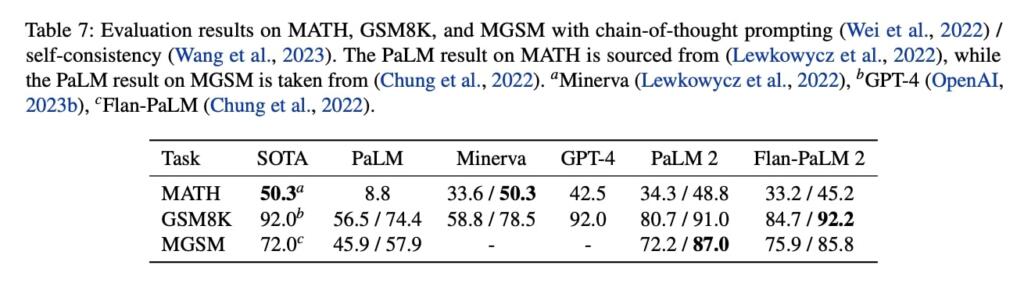
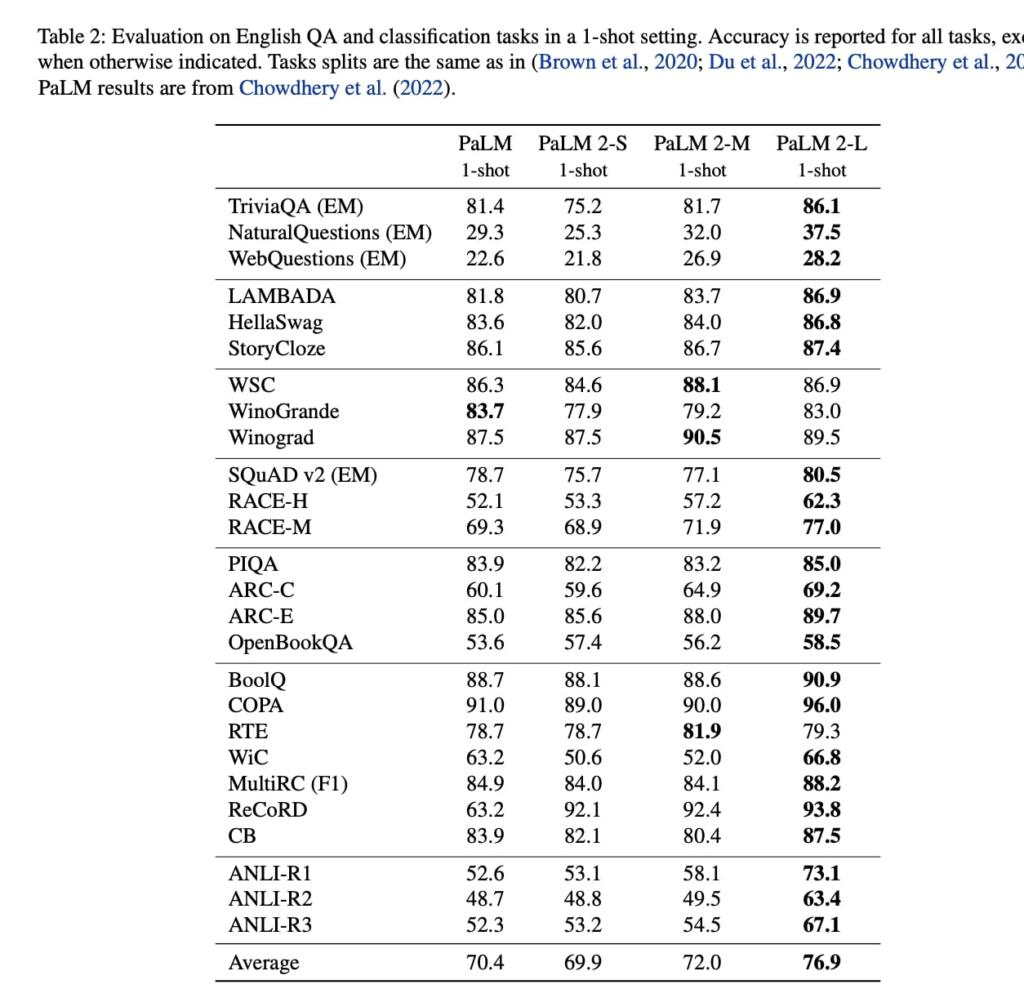
Benchmarks for PaLM-2 beats GPT 4. They use SmartGPT-like techniques to boost performance. PaLM 2 beats even Google Translate, due in large part to the text it was trained on. Coding in Bard, translation, MMLU, Big Bench is very powerful.
Med PaLM 2 could genuinely save thousands of lives.
The largest model in the PaLM 2 family, PaLM 2-L, is significantly smaller than the largest PaLM model but uses more training compute. Their evaluation results show that PaLM 2 models significantly outperform PaLM on a variety of tasks, including natural language generation, translation, and reasoning. These results suggest that model scaling is not the only way to improve performance. Instead, performance can be unlocked by meticulous data selection and efficient architecture/objectives. Moreover, a smaller but higher quality model significantly improves inference efficiency, reduces serving cost, and enables the model’s downstream application for more applications and users. PaLM 2 demonstrates significant multilingual language, code generation and reasoning abilities.
PaLM 2 is the successor to PaLM (Chowdhery et al., 2022), a language model unifying modeling advances, data improvements, and scaling insights.
PaLM 2 incorporates the following diverse set of research advances:
• Compute-optimal scaling: Recently, compute-optimal scaling (Hoffmann et al., 2022) showed that data size is at least as important as model size. They validate this study for larger amounts of compute and similarly find that data and model size should be scaled roughly 1:1 to achieve the best performance for a given amount of training compute (as opposed to past trends, which scaled the model 3× faster than the dataset).
• Improved dataset mixtures: Previous large pre-trained language models typically used a dataset dominated by English text (e.g., ∼78% of non-code). They designed a more multilingual and diverse pre-training mixture, which extends across hundreds of languages and domains (e.g., programming languages, mathematics, and parallel multilingual documents). They show that larger models can handle more disparate non-English datasets without causing a drop in English language understanding performance, and apply deduplication to reduce memorization (Lee et al., 2021)
• Architectural and objective improvements: The model architecture is based on the Transformer. Past LLMs have almost exclusively used a single causal or masked language modeling objective. Given the strong results of UL2 (Tay et al., 2023), They use a tuned mixture of different pre-training objectives in this model to train the model to understand different aspects of language.
Scaling laws
To determine the scaling laws for our configuration, we follow the same procedure as Hoffmann et al. (2022). They train
several differently sized models with 4 different compute budgets: 1×10^19
, 1×10^20
, 1×10^21
, and 1×10^22 FLOPs.
For each compute budget, they use the heuristic FLOPs ≈ 6ND (Kaplan et al., 2020) to determine how many tokens
to train each model for. Critically, they use cosine learning rate decay and ensure that each model’s learning rate fully
decays at its final training token.
Smoothing final validation loss for each model, we perform quadratic fits for each isoFLOPS band.
The minima of those quadratic fits indicate the projected optimal model sizes (N) for each isoFLOPS band.
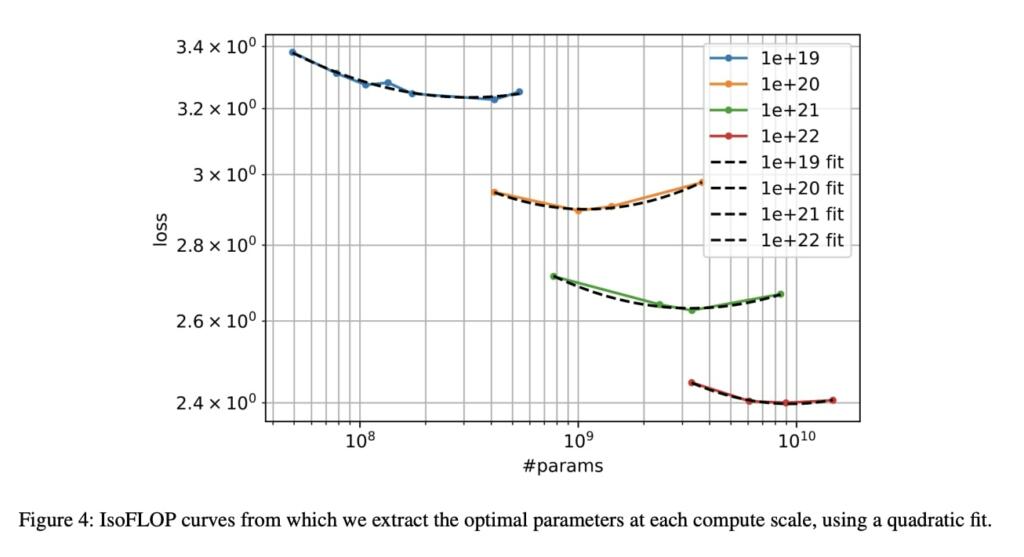
The optimal D is derived from the heuristic FLOPs. Plotting these optimal Ns and optimal Ds against FLOPs, they find that D and N should grow in equal proportions as the FLOPs budget increases. This is a strikingly similar conclusion to Hoffmann et al. (2022), despite that study being conducted at a smaller scale, and with a different training mixture.
They use the scaling laws from
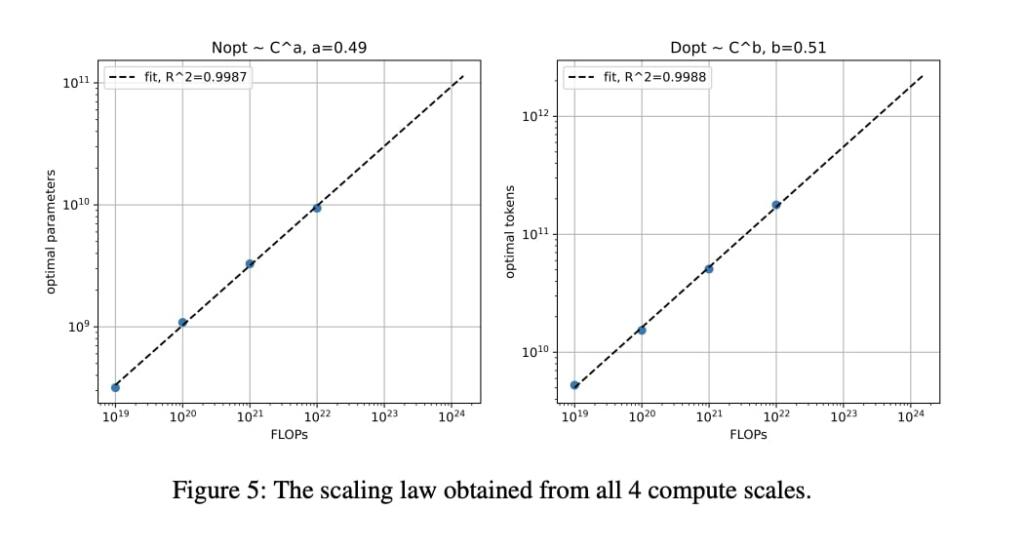
to compute the optimal model parameters (D) and training tokens (N) for
1 × 10^22
, 1 × 10^21 and 1 × 10^20 FLOPs. They then train several models from 400M to 15B on the same pre-training mixture for up to 1×10^22 FLOPs. Finally, they compute loss at the three FLOP points for each model. The resulting training losses and their associated optimal model parameters are included
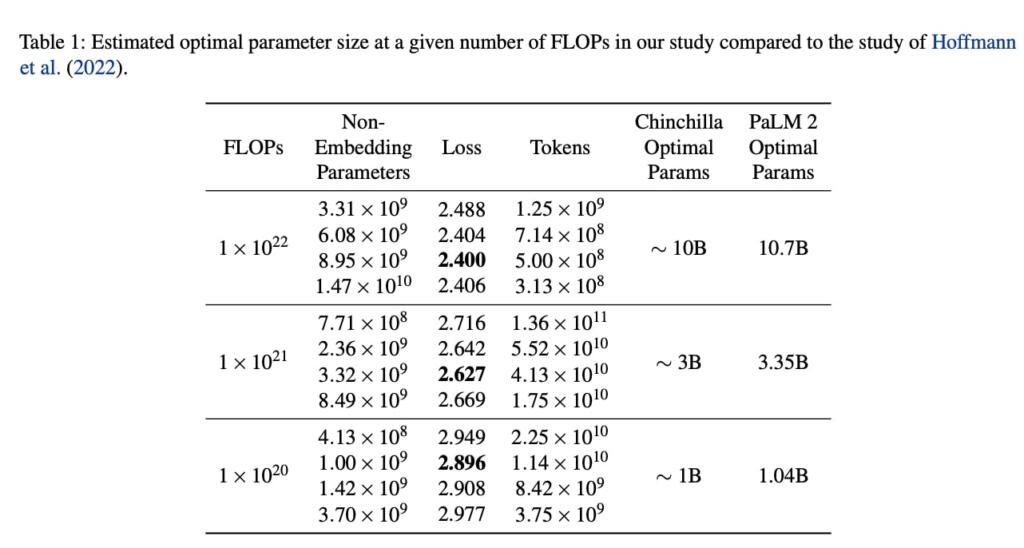
They can observe that the lowest loss is achieved by the models that approximately follow the optimal model parameters (D) given the FLOPs. Please note that all the number of parameters mentioned are non-embedding parameters.
Training Data
The PaLM 2 pre-training corpus is composed of a diverse set of sources: web documents, books, code, mathematics, and conversational data.
They used several data cleaning and quality filtering methods, including de-duplication, removal of sensitive-PII
and filtering. Even though PaLM 2 has a smaller proportion of English data than PaLM, they still observe significant
improvements on English evaluation datasets, as described in Section 4. They attribute this partially to the higher data
quality in the PaLM 2 mixture.



Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
AGI 2023-25