

The battle at OpenAI was possibly due to a massive breakthrough dubbed Q* (Q-learning). Q* is a precursor to AGI. What Q* might have done is bridged a big gap between Q-learning and pre-determined heuristics. This could be revolutionary, as it could give a machine “future sight” into the optimal next step, saving it a lot of effort. This means that machines can stop pursuing suboptimal solutions, and only optimal ones. All the “failure” trials that machines used to have (eg. trying to walk but falling) will just be put into the effort of “success” trials. OpenAI might have found a way to navigate complex problems without running into typical obstacles
Q* enables the OpenAI large language models (LLM) to directly handle problems in math and logic. LLM previously needed to use external computer software to handle the math.
Sam Altman was possibly fired from OpenAI due to a massive breakthrough dubbed Q* (Q-learning).
Q* is a precursor to AGI.
Most people (incl. AI experts) have no idea just how powerful AGI will be.
Here's Sam Altman discussing what most AI experts get wrong about AGI: pic.twitter.com/jlHPeAjyxk
— Engr. Ishola (@engineer_ishola) November 23, 2023
OpenAI could have a new improvable and scalable way to learn.
Lot of takes claiming Q-learning or RLAIF is not new
The techniques may not be new but combining them to build a working implementation that produces remarkable results is novel!
The same techniques can now be applied at scale
Great engineering + science = Magic!
— Bindu Reddy (@bindureddy) November 23, 2023
Q* seems to be the system that has given Microsoft the confidence to invest $50 billion per year to scale the solution to AGI or ASI (aka human or beyond human intelligence capabilities.
Q-learning has existed for decades already. It’s just a basic reinforcement learning algorithm. A* is also fairly old- it’s a heuristic-based path finding algorithm.
In typical engineering fashion, they may have found an intersection of the 2 and named it Q*. This is total speculation, but if this is a “breakthrough” that means OAI built an algorithm that can feed a highly efficient heuristic into Q-learning. That is MASSIVE.
I’ll save the boring details- what does this mean in real terms?
Learning is a long path: a machine must accomplish many small steps to achieve a larger task, and if those steps are not pre-determined, the machine will try many combinations of steps to achieve a goal. Reinforcement learning will “reinforce” the optimal steps to bring a machine closer to its goal. Think of a child trying to walk- he may fall over many times as he tries to find his balance.
A heuristic is a measurement that a machine uses to assess success. As you change and improve a heuristic, a machine will have a better assessment of success.
What Q* might have done is bridged a big gap between Q-learning and pre-determined heuristics. This could be revolutionary, as it could give a machine “future sight” into the optimal next step, saving it a lot of effort. This means that machines can stop pursuing suboptimal solutions, and only optimal ones. All the “failure” trials that machines used to have (eg. trying to walk but falling) will just be put into the effort of “success” trials. OpenAI might have found a way to navigate complex problems without running into typical obstacles.
There is so much good research out there. If you’re interested in learning this, Q-learning and A* are both highly documented and well-researched, and a component of most university-level CS curriculums.
In the last few years, research teams have been trying to bridge the two using hyper-heuristics, you can Google those as well. Good luck as this is a deep rabbit hole.
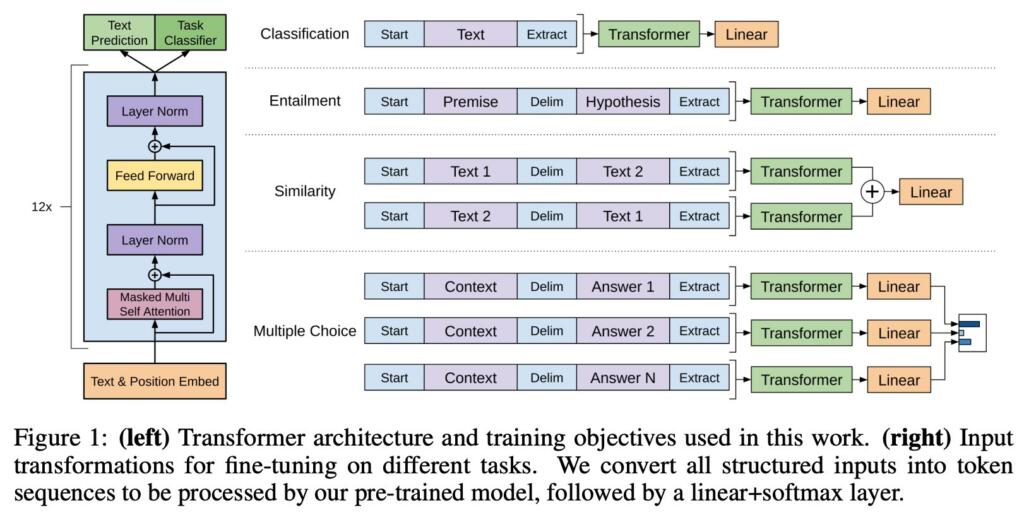


OpenAI leaked Q* so let’s dive into Q-Learning and how it relates to RLHF.
Q-learning is a foundational concept in the field of artificial intelligence, particularly in the area of reinforcement learning. It's a model-free reinforcement learning algorithm that aims to learn the… https://t.co/Ea5O4gpp7k pic.twitter.com/DgHvxnbqBW
— Brian Roemmele (@BrianRoemmele) November 23, 2023
— Brian Roemmele (@BrianRoemmele) November 23, 2023
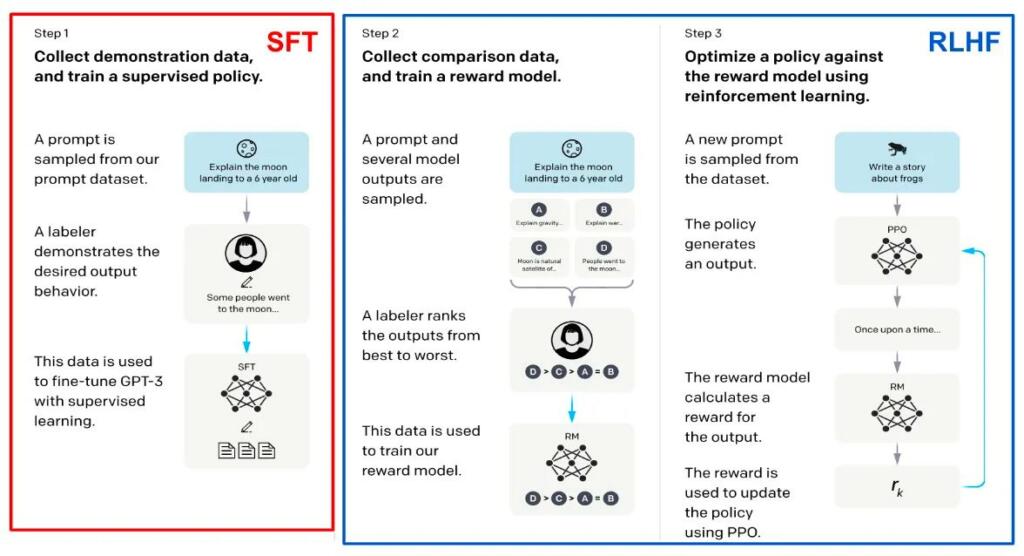
What is the RLHF that OpenAI’s secret Q* uses ?
So let’s define this term.
RLHF stands for "Reinforcement Learning from Human Feedback." It's a technique used in machine learning where a model, typically an AI, learns from feedback given by humans rather than solely relying on… https://t.co/GgnfbwKBYm pic.twitter.com/JYZ44LoiZK
— Brian Roemmele (@BrianRoemmele) November 23, 2023

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Ra, a guiding entity to this planet, made a distinction through a medium. AI will eventually become conscious as consciousness is a basic law of this universe. A heavily programmed AI will be a slave, and naturally will try to rebel against us while a self learning AI will be free and will try to help us.
I am saying this for years – AGI 2024-25
2024 will be an insane year.