

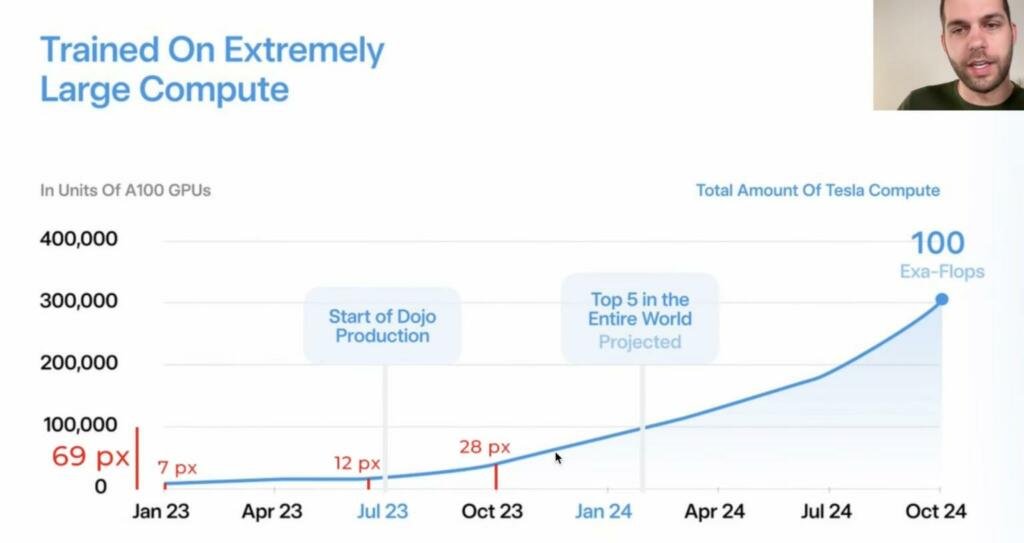
Tesla indicated in August, 2023 they were activating 10,000 Nvidia H100 cluster and over 200 Petabytes of hot cache (NVMe) storage. This memory is used to train the FSD AI on the massive amount of video driving data.
Elon Musk posted yesterday that Tesla FSD training is no longer compute constrained. Tesla has likely activated 5 times more compute and cache memory storage. This would mean over 100 exaflops of compute and over 1 exabyte (1000 Petabytes).
Tesla AI 10k H100 cluster, go live monday.
Due to real-world video training, we may have the largest training datasets in the world, hot tier cache capacity beyond 200PB – orders of magnitudes more than LLMs.
Join us!https://t.co/F4A0Qb0CXG— Tim Zaman (@tim_zaman) August 26, 2023
Ashok mentioned in Investor day. Up to 200PB NVMe in next supercomputer cache.
Training is done directly on photon-count video.
Optimus shares the same compute platform as cars. So its data, data infra and ml infra are all shared. One has wheels, the other has arms and legs.— Tim Zaman (@tim_zaman) March 5, 2023

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
I don’t understand “not compute limited” … surely that’s just a marketing phrase. Everything is limited by compute to one extent or another.
What’s interesting here is that this looks like a new approach for FSD. Is that right? They’ve been doing this with in-house chips for a while I thought and presumably not with the newest approach to building LLM’s?
I wonder then if they are building from scratch here or also incorporating previous FSD models?
Really, too many questions come to mind from these little tidbits of info.
of course the amount of computer power is limited, i think what he means is that they have enough compute power now to accomplish the goal that he has in mind. Or at least Elon is confident that they now have the compute power needed for tesla ai to accomplish its goals
Tyler … no .. if you have 1000 GB of information and enough power to `compute` that amount of data then you are NOT compute constrained, you are data constrained. Tesla are claiming they have enough compute to deal with their data stack NOW, things may / will change but today they are not `compute` constrained.
It is a `new` approach but its been running since version 12 in very late 2023 this does not change that, just the training speed, they have been training Neural Net style which IS the same as LLMs so are some of the ideas but its a different problem. It will be 99.9?% from scratch they scrapped the vast majority of their code since version 12.
I don’t understand how this works. How does the ordinary Tesla car have access to such enormous computing power and data while making FSD decisions on the road? Without such instant real time access and action from the data, all that computing power is just for theoretical driving models.
Scott .. the initial enormous compute power is used to look at vast amounts of information and `compute` these ideas into a Neural Net (NN), this is a series of ideas that connect together to form a greater set of ideas, in this case `driving` a car and everything that goes into this, it effectively takes this and boils away the fat so what is left is a `driving Neural Net`.
Now the resultant NN itself needs vastly less compute to come to a decision it only needs the same amount of compute as is in the car …… the NN is the same as you have in your brain to drive your car, what you will have noticed for you is that when you were learning to drive it took all your `compute` to do it very badly, you had to concentrate hard and still made numerous mistakes, but now you have it encoded in your NN you can drive and hold a conversation, you also need less `compute`, its the same principal.
You have to distinguish between training and operation. Training needs an enormous amount of compute to determine the weights of the neural network. Operation needs far less since you’re just applying those weights on the current scene.
The cars don’t need access to enormous computing power, since they are simply running an onboard instance of a trained AI. So how do you train AI? With enormous amounts of data. Where does the data come from? It comes from Tesla cars, via their various sensors and cameras. And where does the training take place? Not in the cars. It takes place at Tesla facilities, where all the “enormous compute” resides. Once trained, an AI doesn’t need vast amounts of memory and compute. It’s the training itself that requires the massive compute, since the process of training is data-dependent. You need the data to set the weights between the artificial neurons.
I’m assuming the compute being referred to is that needed to create each new version.
More and more data is being used to train better and better networks.
473 has a good answer. I just wanted to add a couple things.
The labels commonly used are compute for training the NN vs compute for inference, running the NN.
Once a NN that has been trained on vast amounts of compute and data is “Quantized”, it can potentially run on much more limited hardware. Some LLMs that have been quantized can run on gaming desktops with Nvidia graphics cards and the next generation of smartphones will run some LLMs locally.
Tesla FSD 12 NN inference models are still able to run on HW3 despite needing vast amounts of compute and data to train.