

Professor Ross D King and his team have demonstrated for the first time the feasibility of engineering a nondeterministic universal Turing machine (NUTM), and their research is to be published in the prestigious Journal of the Royal Society Interface.
* A major motivation for this work is to engineer a general-purpose way of controlling cells
The theoretical properties of such a computing machine, including its exponential boost in speed over electronic and quantum computers, have been well understood for many years – but the Manchester breakthrough demonstrates that it is actually possible to physically create a NUTM using DNA molecules.
“Imagine a computer is searching a maze and comes to a choice point, one path leading left, the other right,” explained Professor King, from Manchester’s School of Computer Science. “Electronic computers need to choose which path to follow first.
“But our new computer doesn’t need to choose, for it can replicate itself and follow both paths at the same time, thus finding the answer faster.
“This ‘magical’ property is possible because the computer’s processors are made of DNA rather than silicon chips. All electronic computers have a fixed number of chips.
“
Our computer’s ability to grow as it computes makes it faster than any other form of computer, and enables the solution of many computational problems previously considered impossible.
Professor Ross D King
DNA computing trades space for time: ‘there’s plenty of room at the bottom. This gives it potential advantages in speed, energy efficiency and information storage over electronics:the number of operations for a desktop DNA computer could plausibly be ~10^20s (about one thousand times faster than the fastest current super-computer); it could execute ~2 ×10^19operations per Joule (~10 billion times more energy efficient than current computers); and utilise memory with an information density of ~1 bit per nm3(~10^1 2more dense than current memory). These advantages mean that it is feasible that a DNA NUTM based computer could outperform all standard computers on significant practical problems. Our design for a NUTM physically embodies an abstract NUTM. Due to noise the correspondence between a NUTM and its DNA implementations is less good than that between UTMs and electronic computers. Although noise was a serious problem in the early days of electronic computers,it has now essentially been solved.
Compared to Quantum Computers(QCs) noise is far less a problem for DNA NUTM as there are multiple well established ways to control it, e.g. use of restriction enzymes/CRISPR to eliminate DNA sequences that do not encode symbols, use of error-correcting codes, repetition of computations, amplification of desired sequences, etc . Most significantly, when a NP problem is putatively solved the answer can be efficiently checked using an electronic computer in P time.
The implementation of this DNA computer could have as effectors RNA/proteins generated using special sequences and RNA polymerase, etc. The current in vitro implementation of a NUTM is not suitable for this. However, it would seem possible to implement the core ideas in a biological substrate. One way to do this would be to use plasmids as programs, and rolling circle replication.
Given the prospect of engineering a NUTM it is natural to consider whether machines could be physically engineered for other complexity classes. A problem is a member of the class co-NP if and only if its complement is in the complexity class NP. The definition of NP uses an existential mode of computation: if any branch of the computation tree leads to an accepting state, then the whole computation accepts. The definition of co-NP uses a universal mode of computation: if all branches of the computation tree lead to an accepting state then the whole computation accepts. It would therefore be straightforward to adapt out NUTM design to compute co-NP problems: all accepting states are removed from the mixing vessel.
It would also be straightforward to add randomisation to a physical NUTM (through the use of thermal noise). The class BPP (Bounded-Error Probabilistic Polynomial-Time) is the class of decision problems where there exists a P time randomised algorithm. Although the relationship between BPP and NP is unknown, it would seem computationally useful to generate an exponential number of randomised UTMs in P time, for example for simulations.
The complexity class PSPACE consists of those problems that can be solved by a Turing machine (deterministic or nondeterministic) using a polynomial amount of space. It is a superset of NP, but it is not known if this relation is strict i.e. if NP = PSPACE. In an NUTM all the computation is in a sense local: forks with no communication between computational paths. We hypothesise that a requirement for local computation is a fundamental definition of the NP class. In contrast, a physical PSPACE computer would seem to require highly efficient communication between computational paths, which seems challenging. We therefore conjecture that it is physically impossible to build a computer that can efficiently solve PSPACE complete problems.
NUTMs and QCs both utilize exponential parallelism, but their advantages and disadvantages seem distinct. NUTM’s utilize general parallelism, but this takes up physical space. In a QC the parallelism is restricted, but does not occupy physical space (at least in our Universe). In principle therefore it would seem to be possible to engineer a NUTM capable of utilizing an exponential number of QCs in P time.
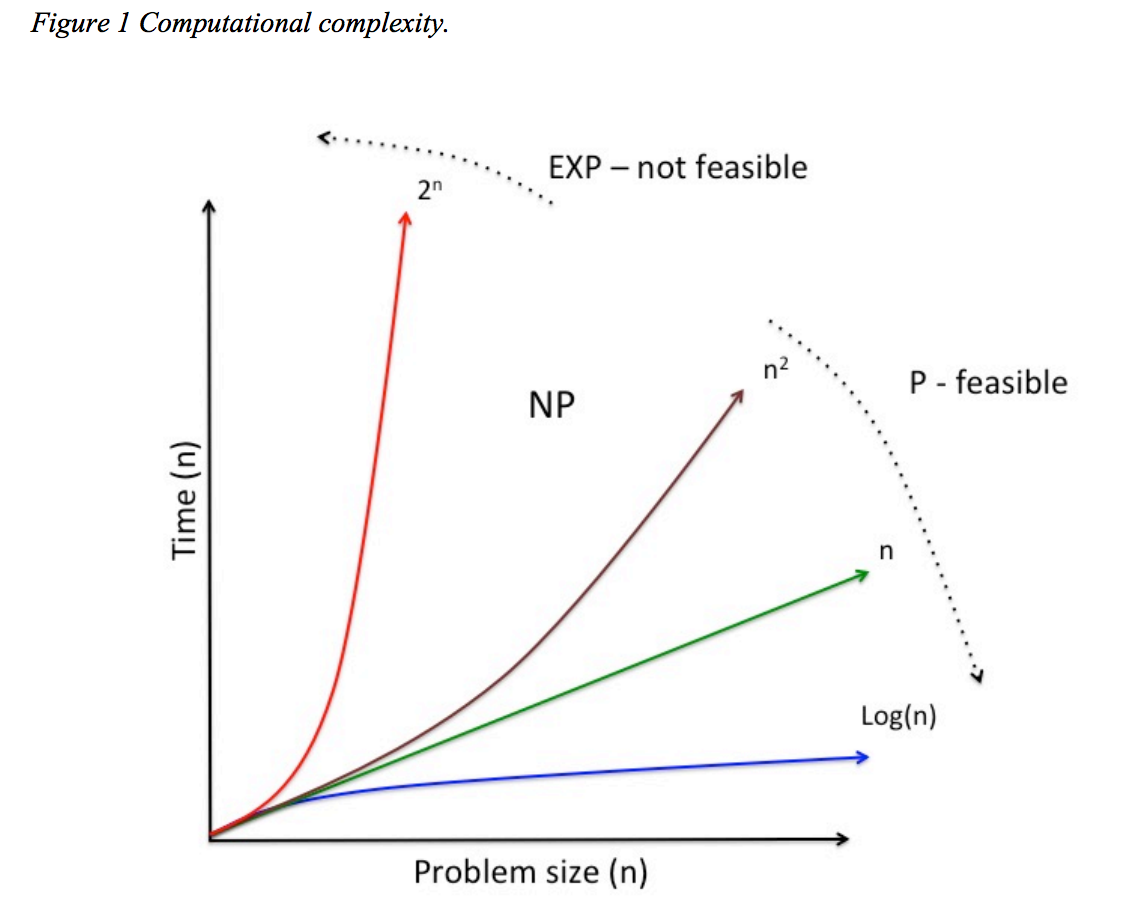
A) The feasibility thesis asserts that there is a fundamental qualitative difference between algorithms that run in Polynomial time (P time) (e.g. schoolbook multiplication), and algorithms that run in exponential time (EXP time) (e.g. position evaluation in a generalised game). As problem size increases P time algorithms can still feasibly (efficiently) be executed on a physical computer, whereas EXP time algorithms cannot. The feasibility thesis also asserts that NP algorithms cannot feasibly be executed, but this is less clear as this assumes P ≠ NP.


Arxiv – Computing exponentially faster: Implementing a nondeterministic universal Turing machine using DNA
“Quantum computers are an exciting other form of computer, and they can also follow both paths in a maze, but only if the maze has certain symmetries, which greatly limits their use.
“As DNA molecules are very small a desktop computer could potentially utilize more processors than all the electronic computers in the world combined – and therefore outperform the world’s current fastest supercomputer, while consuming a tiny fraction of its energy.”
The University of Manchester is famous for its connection with Alan Turing – the founder of computer science – and for creating the first stored memory electronic computer.
“This new research builds on both these pioneering foundations,” added Professor King.
Alan Turing’s greatest achievement was inventing the concept of a universal Turing machine (UTM) – a computer that can be programmed to compute anything any other computer can compute. Electronic computers are a form of UTM, but no quantum UTM has yet been built.
Abstract
The theory of computer science is based around Universal Turing Machines (UTMs): abstract machines able to execute all possible algorithms. Modern digital computers are physical embodiments of UTMs. The nondeterministic polynomial (NP) time complexity class of problems is the most significant in computer science, and an efficient (i.e. polynomial P) way to solve such problems would be of profound economic and social importance. By definition nondeterministic UTMs (NUTMs) solve NP complete problems in P time. However, NUTMs have previously been believed to be physically impossible to construct. Thue string rewriting systems are computationally equivalent to UTMs, and are naturally nondeterministic. Here we describe the physical design for a NUTM that implements a universal Thue system. The design exploits the ability of DNA to replicate to execute an exponential number of computational paths in P time. Each Thue rewriting step is embodied in a DNA edit implemented using a novel combination of polymerase chain reactions and site-directed mutagenesis. We demonstrate that this design works using both computational modelling and in vitro molecular biology experimentation. The current design has limitations, such as restricted error-correction. However, it opens up the prospect of engineering NUTM based computers able to outperform all standard computers on important practical problems.
SOURCES Arxiv, University of Manchester

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.