
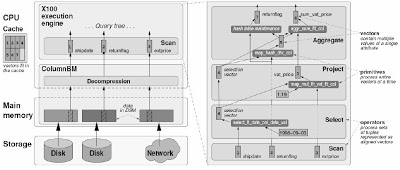

The figure below shows the architecture of the new VectorWise engine. The
left part shows the system architecture (“X100” execution engine and
ColumnBM buffer manager) and how it maps on the computer resources
(CPU cache, RAM and disk). The right part shows a query in action, having
been decomposed into so-called relational operators (Aggregate, Project,
Select and Scan) and execution primitives (such as summation –
aggr_sum_flt_col).
The Ingres VectorWise project team has worked with Intel to evaluate database performance on the new Intel Xeon processor 5500 series based platform. To date, the results of the project have demonstrated dramatic cost and performance capabilities as evidenced by nearly 80 fold speed up on a query modelled after the Q1 query of TPC-H3 suite on the Intel Xeon processor.
VectorWise next-generation database technology is based on a novel query processing architecture that allows modern microprocessors and memory architectures to reach their full potential. This is a unique achievement: in detail studies that compare common computing tasks such as scientific calculation, multi-media authoring, games, and databases have consistently shown that typical database engines do not benefit from new processor performance features such as SSE, out of order execution, chip multithreading, and increasingly larger L2/L3 caches due to their large, complex legacy code structure.
The computational power that database systems provide is known to be lower than the performance realized by hand-coding the same task in a (e.g. C++) program. However, the actual performance difference can be surprisingly large: a factor 100. VectorWise has created the first database system to revert that situation, with dramatic efficiency improvements as a result
.
Vectorized Execution
The VectorWise engine is designed for in-cache execution, which means that the only “randomly” accessible memory is the CPU cache, and main memory (by now inappropriately named “RAM” – Random Access Memory) is already considered part of secondary storage, used in the buffer manager for buffering I/O operations and their compressed large intermediate results. Queries are processed by passing on multiple tuples at a time between relational operators, called “vectors.” These vectors are at the heart of the execution engine:
• VectorWise has developed vectorized versions of relational operators, so there is vectorized selection, vectorized project, join, sort etc. It has even been possible to vectorize binary search.
• Vectors are the simplest possible data structure, an array of values. A tuple is represented as a set of vectors of the same length, one for each column.
• An optional selection vector contains the positions of the tuples currently taking part in processing, i.e. those that have passed a filter operation.
• A vector contains typically between 100-1000 values. The vector size is tuned such that all vectors in a query plan fit comfortably together in the CPU cache.
• Vectorized primitives have many performance advantages because methods perform 100-1000 times more work, function call overhead is dramatically reduced, and database code becomes much more local, improving instruction cache locality and CPU branch prediction.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.