

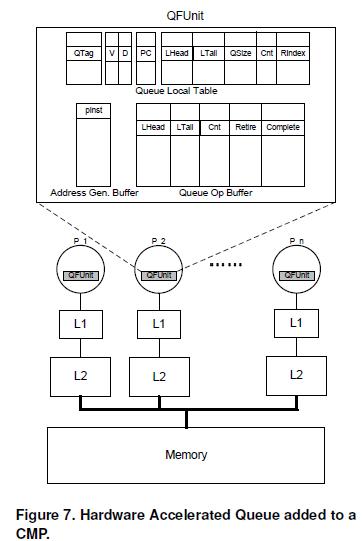
The technology, called HAQu, is “not hardware designed to communicate data on its own, but is hardware that expedites data-sharing using existing data paths on a computer chip.” Because HAQu uses these existing data paths, the research team compared it to software communication tools – even though it is a piece of hardware.
HAQu is also more energy efficient. “It actually consumes more power when operating but, because it runs so much more quickly, the overall energy consumption of the chip actually decreases,” Tuck says.
The next step for the research team is to incorporate the hardware into a prototype system to demonstrate its utility in a complex software environment.
The paper, “HAQu: Hardware-Accelerated Queueing for Fine-Grained Threading on a Chip Multiprocessor,” is co-authored by Tuck, NC State Ph.D. students Sanghoon Lee and Devesh Tiwari, and Dr. Yan Solihin, an associate professor of electrical and computer engineering at NC State. The paper will be presented Feb. 14 at the International Symposium on High-Performance Computer Architecture in San Antonio, Texas.
HAQu: Hardware-Accelerated Queueing for Fine-Grained Threading on a Chip Multiprocessor (12 pages)
Automatic Parallelization of Fine-Grained Meta-Functions
on a Chip Multiprocessor (11 pages)
HAQu: Hardware-Accelerated Queueing for Fine-Grained Threading on a Chip Multiprocessor
Authors: Sanghoon Lee, Devesh Tiwari, Yan Solihin, James Tuck, North Carolina State University
Presented: Feb. 14, 2011, at the International Symposium on High-Performance Computer Architecture in San Antonio, Texas
Abstract: Queues are commonly used in multithreaded programs for synchronization and communication. However, because software queues tend to be too expensive to support finegrained parallelism, hardware queues have been proposed to reduce overhead of communication between cores. Hardware queues require modifications to the processor core and need a custom interconnect. They also pose difficulties for the operating system because their state must be preserved across context switches. To solve these problems, we propose a hardware-accelerated queue, or HAQu. HAQu adds hardware to a CMP that accelerates operations on software queues. Our design implements fast queueing through an application’s address space with operations that are compatible with a fully software queue. Our design provides accelerated and OS-transparent performance in three general ways: (1) it provides a single instruction for enqueueing and dequeueing which significantly reduces the overhead when used in fine-grained threading; (2) operations on the queue are designed to leverage low-level details of the coherence protocol ; and (3) hardware ensures that the full state of the queue is stored in the application’s address space, thereby ensuring virtualization. We have evaluated our design in the context of application domains: offloading fine-grained checks for improved software reliability, and automatic, fine-grained parallelization using decoupled software pipelining.
We evaluated HAQu on queueing micro benchmarks, the parallelization of Mudflap, and Decoupled Software Pipelining. Compared to FastForward and Lee et al , HAQu achieved speedups of 7X and 6.5X. We found that HAQu can deliver high throughput and low latency queueing, and that it carried over to application level studies. The low instruction footprint of each queue operation frees the processor to perform other tasks, thereby enabling finegrained parallelism. Furthermore, HAQu is able to scale-up and attain high throughput on next generation interconnects. In conclusion, HAQu is a modest architectural extension that can help parallel programs better utilize the interconnect and processing capability of future CMPs
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
