
Rex Computing will be sampling its first chips in the middle of 2016 and will move to full production silicon in mid-2017 using TSMC’s 28 nanometer process.
To do this, they are throwing out the feature creep and bloat of processors of the past 30 years, and using improvements in the world of software to greatly simplify the processor itself to only what is necessary.
In doing so, they are able to deliver a 10 to 25x increase in energy efficiency for the same performance level compared to existing GPU and CPU systems
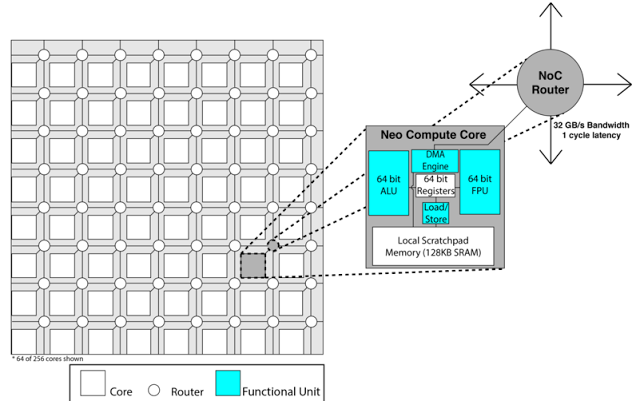
256 Cores per chip
Scratchpad memory
A 2D-Mesh Interconnect
Revolutionry high bandwidth chip to chip interconnect
256 GFLOPs DP or 512 GFLOPs SP
at 64 to 128 GFLOPs/watt
Same performance for integer calculations.
Balanced memory bandwidth allows near-theoretical peak performance.
Extreme scalability: near limitless number of Neo chips per node.


DARPA ($100,000) and venture funding ($1.25 million) is designed to target the automatic scratch pad memory tools, which, according to Sohmers is the “difficult part and where this approach might succeed where others have failed is the static compilation analysis technology at runtime.”
Neo will be similar to tapping a cache-based system but without all the area and power overhead. Rex’s goal is to remove unnecessary complexity in the on-processor memory system and put that into the compiler instead. All of this happens at compile time, so it does not add complexity to the program itself either. The compiler understands where data will need to be at different points and it inserts it where it should go instead of leaving it in DRAM and letting the chip’s memory management units fetch it when it needs to in an inefficient big handful—and with data included that likely will not be used anyway.
“It takes 4200 picojoules to move 64 bits from DRAM to registers while it only takes 100 picojoules to do a double-precision floating point operation. It’s over 40x more energy to move the data than to actually operate on it. What most people would assume is that most of that 4200 picojoules is being used in going off-chip, but in reality, about 60% of that energy usage is being consumed by the on-chip cache hierarchy because of all of the extra gates and wires on the chip that the electrons go through. We are removing that 60%.
Even with funding, this is a risky venture. “The cost for us going to TSMC and getting 100 chips back is, after you include the packaging and just getting the dies to our door, around $250,000. They sell them in blocks with shared costs of the mask among other companies, which is how we’re getting our first prototypes made.” Before that the other costs are EDA tools. Single seats for Cadence or Synopsys software is in the several hundreds of thousands of dollars even when you’re a startup, he says.
SOURCES – Rex Computing, Nextplatform, Golem.de

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.