

There is work to mitigate, detect and prevent the hallucinated bad results from Generative AI like ChatGPT. One current general research challenge in NLP is to establish a means of identifying hallucinated texts without the need to entirely redesign new NLP (AI) models that incorporate, define and authenticate facts as discrete entities. Authenticating all facts would be a longer-term, separate goal in a number of wider computer research sectors. There are different AI systems which hold authenticated facts. The generative AI and more precise systems could be used for immediate verification of results. There is need to maintain low cost and high speed in the solutions for better AI.
Neural sequence models can generate highly fluent sentences, but recent studies have also shown that they are also prone to hallucinate additional content not supported by the input. These variety of fluent but wrong outputs are particularly problematic, as it will not be possible for users to tell they are being presented incorrect content. To detect these errors, researchers propose a task to predict whether each token in the output sequence is hallucinated (not contained in the input) and collect new manually annotated evaluation sets for this task. They also introduce a method for learning to detect hallucinations using pretrained language models fine tuned on synthetic data that includes automatically inserted hallucinations Experiments on machine translation (MT) and abstractive summarization demonstrate that our proposed approach consistently outperforms strong baselines on all benchmark datasets. They further demonstrate how to use the token-level hallucination labels to define a fine-grained loss over the target sequence in low-resource MT and achieve significant improvements over strong baseline methods. They also apply their method to word-level quality estimation for MT and show its effectiveness in both supervised and unsupervised settings.
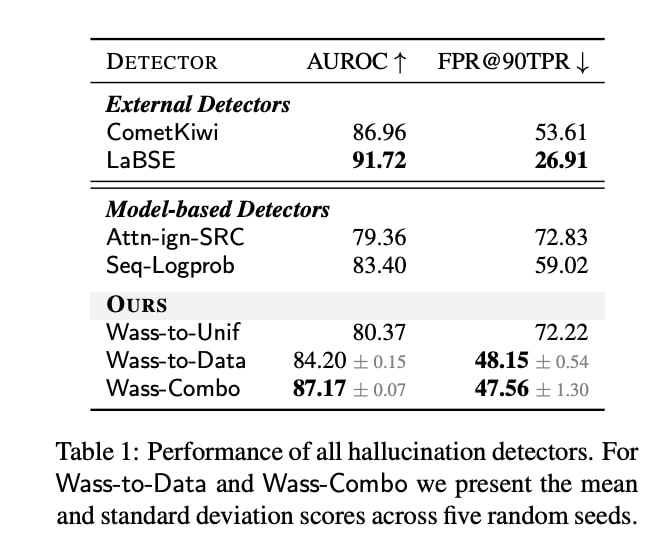
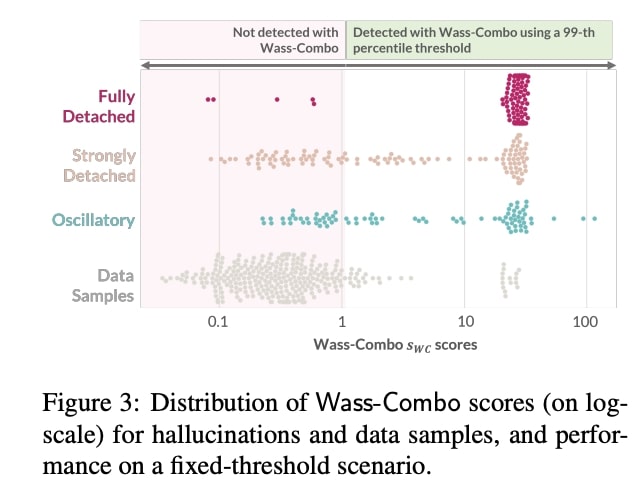
Neural machine translation (NMT) has become the de-facto standard in real-world machine translation applications. However, NMT models can unpredictably produce severely pathological translations, known as hallucinations, that seriously undermine user trust. It becomes thus crucial to implement effective
preventive strategies to guarantee their proper functioning. In this paper, we address the problem of hallucination detection in NMT by following a simple intuition: as hallucinations are detached from the source content, they exhibit encoder-decoder attention patterns that are statistically different from those of good quality translations. We frame this problem with an optimal transport formulation and propose a fully unsupervised, plug-in detector that can
be used with any attention-based NMT model. Experimental results show that our detector not only outperforms all previous model-based detectors, but is also competitive with detectors that employ large models trained on millions of samples.



Characterizing Attribution and Fluency Tradeoffs for Retrieval-Augmented Large Language Models
Despite recent progress, it has been difficult to prevent semantic hallucinations in generative Large Language Models. One common solution to this is augmenting LLMs with a retrieval system and making sure that the generated output is attributable to the retrieved information. Given this new added constraint, it is plausible to expect that the overall quality of the output will be affected, for example, in terms of fluency. Can scaling language models help?
Here we examine the relationship between fluency and attribution in LLMs prompted with retrieved evidence in knowledge-heavy dialog settings. Our experiments were implemented with a set of auto-metrics that are aligned with human preferences. They were used to evaluate a large set of generations, produced under varying parameters of LLMs and supplied context. We show that larger models tend to do much better in both fluency and attribution, and that (naively) using top-k retrieval versus top-1 retrieval improves attribution but hurts fluency. We next propose a recipe that could allow smaller models to both close the gap with larger models and preserve the benefits of top-k retrieval while avoiding its drawbacks.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
Technically, you could say that the models are hallucinating ALL of their output, it’s just that their delusions are so well aligned with reality that most of the time they happen to be accurate.