

ChatGPT, GPT-4 are Large Language Models (LLM). There are four major aspects of LLMs pre-training, adaptation tuning, utilization, and capacity evaluation. Here is one of the new summaries of the available resources for developing LLMs and issues for future directions.
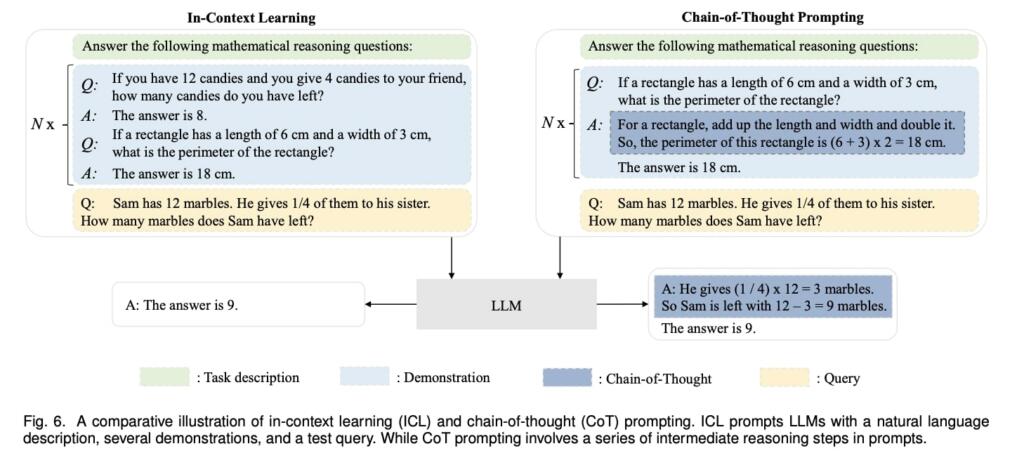
Chain-of-Thought (CoT) is an improved prompting strategy to boost the performance of LLMs on complex reasoning tasks, such as arithmetic reasoning, commonsense reasoning, and symbolic reasoning. Instead of simply constructing the prompts with input-output pairs as in ICL, CoT incorporates intermediate reasoning steps that can lead to the final output into the prompts.
CoT is an emergent ability, it only has a positive effect on sufficiently large models (e.g., typically containing 10B or more parameters) but not on small models. Moreover, since CoT augments the standard prompting with intermediate reasoning steps, it is mainly effective to improve the tasks that require step-by-step reasoning, such as arithmetic reasoning, commonsense reasoning, and symbolic reasoning.
CAPACITY EVALUATION
To examine the effectiveness and superiority of LLMs, a surge of tasks and benchmarks have been leveraged for conducting empirical evaluation and analysis. Researchers first introduce three types of basic evaluation tasks of LLMs for language generation and understanding, then present several advanced tasks of LLMs with more complicated settings or goals, and finally discuss existing benchmarks and empirical analyses.
Basic Evaluation Tasks
Evaluators mainly focus on three types of evaluation tasks for LLMs, i.e., language generation, knowledge utilization, and complex reasoning.
Existing tasks about language generation can be roughly categorized into language modeling, conditional text generation, and code synthesis tasks.
Language Modeling. As the most fundamental ability of LLMs, language modeling aims to predict the next token based on the previous tokens, which mainly focuses on the capacity of basic language understanding and generation. For evaluating such an ability, typical language modeling datasets that existing work uses include Penn Treebank, WikiText-103, and the Pile, where the metric of perplexity is commonly used for evaluating the model performance under the zero-shot setting. Empirical studies show that LLMs bring substantial performance gains over the previous state-of-the-art methods on these evaluation datasets.
Conditional Text Generation. As an important topic in language generation, conditional text generation focuses on generating texts satisfying specific task demands based on the given conditions, typically including machine translation, text summarization, and question answering. To measure the quality of the generated text, automatic metrics (e.g., Accuracy, BLEU and ROUGE) and human ratings have been typically used for evaluating the performance. Due to the powerful language generation capabilities, LLMs have achieved remarkable performance on existing datasets and benchmarks, even surpassing human performance (on test datasets).
Code Synthesis. Besides generating high-quality natural language, existing LLMs also show strong abilities to generate formal language, especially computer programs (i.e., code) that satisfy specific conditions, called code synthesis. Generated code can be directly checked by execution with corresponding compilers or interpreters, existing work mostly evaluates the quality of the generated code from LLMs by calculating the pass rate against the test cases. Recently, several code benchmarks focusing on functional correctness are proposed to assess the code synthesis abilities of LLMs, such as APPS, HumanEval, and MBPP.
Knowledge Utilization
Knowledge utilization is an important ability of intelligent systems to accomplish knowledge-intensive tasks (e.g., commonsense question answering and fact completion) based on supporting factual evidence. Concretely, it requires LLMs to properly utilize the rich factual knowledge from the pretraining corpus or retrieve external data when necessary. In particular, question answering (QA) and knowledge completion have been two commonly used tasks for evaluating this ability. According to the test tasks (question answering or knowledge completion) and evaluation settings (with or without external resources), they categorize existing knowledge utilization tasks into three types, namely closed-book QA, open-book QA, and knowledge completion.
Major Issues : Hallucination and knowledge recency beyond the training dataset.
Complex Reasoning
Complex reasoning refers to the ability of understanding and utilizing supporting evidence or logic to derive conclusions or make decisions. According to the type of involved logic and evidence in the reasoning process, they consider dividing existing evaluation tasks into three major categories, namely knowledge reasoning, symbolic reasoning, and mathematical reasoning.
Major Issues: Inconsistency and Numerical Computation
Advanced Ability Evaluation
In addition to the above basic evaluation tasks, LLMs also exhibit some superior abilities that require special considerations for evaluation. Researchers looked at several representative advanced abilities and the corresponding evaluation approaches, including human alignment, interaction with the external environment, and tool manipulation.
Application and Ecosystem.
LLMs have shown a strong capacity in solving various tasks, they can be applied in a broad range of real-world applications.
They can change how humans access information, which has been implemented in the release of New Bing.
In the near future, it can be foreseen that LLMs would have a significant impact on information-seeking techniques, including both search engines and recommender systems. Furthermore, the development and use of intelligent information assistants would behighly promoted with the technology upgrade from LLMs.
In a broader scope, this wave of technical innovation would lead to an ecosystem of LLM-empowered applications (e.g., the support of plugins by ChatGPT), which has a close connection with human life. Lastly, the rise of LLMs sheds light on the exploration of artificial general intelligence (AGI). It is promising to develop more smart intelligent systems (possibly with multi-modality signals) than ever. However, in this development process, AI safety should be one of the primary concern.







Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
I’ve been working with ChaptGPT 3.5 on data mapping using CSV representations of source and target data dictionaries. I can tell it where in the CSV record to find the values for the responses – and it still hallucinates values.
This is a massive barrier to adoption. It will certainly get better, but the models will improve far faster than trust in their output will be gained.