
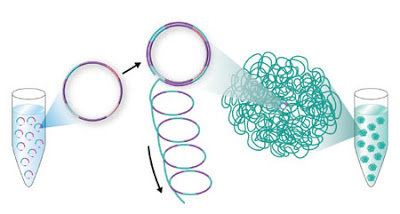

An 80-base-pair piece of DNA to be sequenced (shown here in purple) is first inserted into a circular template of DNA, along with four stretches of synthetic DNA, called adaptors (pink and blue). A specialized enzyme then makes hundreds of consecutive copies of the DNA circle. Thanks to chemical properties engineered into the adaptor sequences, this long piece of DNA spontaneously forms into a compact ball of DNA, called the DNA nanoball. Credit:Complete Genomics
Complete Genomics goal is to become the global leader in human genome sequencing. They are a startup that has received $46 million in venture funding to date.
Complete Genomics is working with the Institute for Systems Biology (ISB) to sequence the genomes of 100 individuals in 2009 and 2000 individuals by in 2010. The ISB project with Leroy Hood. The project will use about ten percent of Complete Genomics facilities sequencing capacity in the first two years. So Complete Genomics could sequence 1000 individuals in 2009 and 20,000 individuals in 2010.
Complete Genomics says that its cheap price tag comes thanks to two innovations: a way to densely pack DNA, developed by Rade Drmanac, the company’s chief scientific officer, and a method to randomly read DNA letters, based on sequencing technology developed at George Church’s lab at Harvard.
To start with, an 80-base-pair piece of DNA is inserted into a circular piece of synthetic DNA and replicated 1,000 times with a specialized enzyme. That large aggregate of DNA spontaneously compresses into a tightly packed ball, thanks to chemical characteristics engineered into the synthetic DNA. These DNA “nanoballs” are then packed onto specially fabricated arrays with unprecedented density–about a billion balls fit on a chip the size of a microscope slide. The high density of DNA allows large volumes to be sequenced quickly with few reagents, one of the most costly components of the process.
Next, as with other approaches, Complete Genomics determines the sequence of the target DNA using a series of fluorescently labeled DNA strands designed to bind to corresponding letters. But while advanced sequencing technologies currently in use–including those from Illumina, Applied Biosystems, and 454–read the sequence sequentially, letter by letter, Complete Genomics’s labels bind to the target DNA randomly. Both the labels and the DNA circle are designed to allow scientists to deduce the position of each highlighted base–information that is then used to computationally reconstruct the sequence of the target DNA. (With both Complete Genomics’s and other companies’ methods, the short strands are computationally stitched together to generate the entire genome sequence.
Because the identification of each base in the sequence does not depend on the correct identification of the previous one, individual errors have less impact on the overall result, generating a more accurate sequence with less repeat sequencing

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.