

The exact plans that Fujitsu has for its future ARM processor were not divulged at ISC16, but Yutaka Ishikawa, project leader for the Advanced Institute of Computational Science located in RIKEN’s Kobe, Japan facility, confirmed not only that the successor to the K supercomputer, which is being developed under the Flagship2020 program, would use ARM-based processors but that these chips would be at the heart of a new system built by Fujitsu for RIKEN that would break the exaflops barrier by 2020.
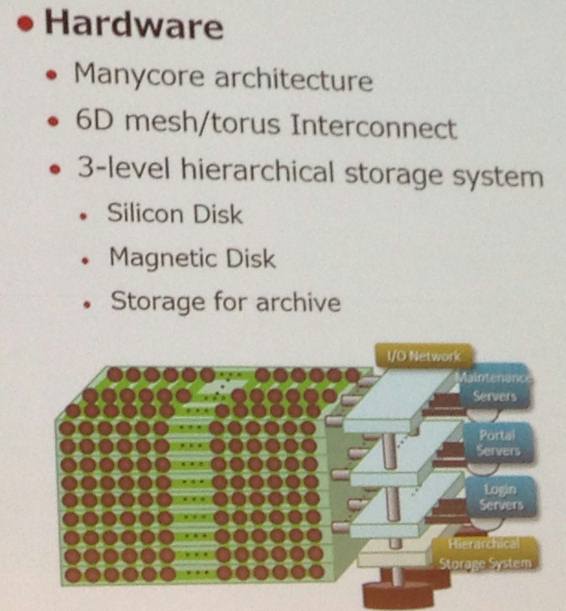
In his presentation at ISC16, Ishikawa said that the target performance of the Post-K machine was for it to be 100 times that of K in terms of capacity computing and 50 times that of K when looked at through capability computing, which is a way of saying 100X on peak flops and 50X on real-world applications that will probably not go anywhere near the exaflops level in their scalability. What that means is that Fujitsu is committing to delivering a machine with more than 1 exaflops of aggregate peak performance, and you can be pretty sure that there will be enough extra performance in the box so the Linpack number will break 1 exaflops. The system is expected to consume somewhere between 30 MW and 40 MW.
The exascale target of a 25 MW system by 2020 was always optimistic. They may be willing to pay for more electricity to get to exaflops earlier so long as this much power can be brought into centers like RIKEN. The K super burns 12.7 megawatts. Those numbers are for the compute and storage part of the system and does not include the power distribution and cooling within the datacenter that wraps around them, which takes an enormous amount of energy.
The post K computer is the successor of K computer, that will be the next Japanese flagship machine, being developed by RIKEN. It will be operated from 2020. The post T2K computer, whose peak performance will be about 30 PF, is being designed under the joint project of two universities, Tsukuba and Tokyo, and will be operated from 2016.
Japan’s 2020 project has a budget of about US$910 million
So what could Post-K look like from a processor perspective?
The next logical jump for Fujitsu with the Sparc64 chips was to a 16 nanometer process and another core shrink, perhaps to 48 cores on a die. The drop down to 10 nanometer in 2019 or so might have allowed it to put as many as 64 cores to 96 cores on a die. So just holding clock speeds steady and raising core counts would have gotten Fujitsu to somewhere between 200 petaflops and 300 petaflops two Sparc64 fx generations from now. Double up the SIMD units to 512 bits each, and you can hit 400 petaflops to 600 petaflops. Scale out the interconnect with Tofu3, and if you did maybe 165,000 nodes instead of 100,000 max, that gets you to 1 exaflops peak with a core running at about 2.2 GHz. Global replacing Sparc64 fx cores with ARMv8 cores in such designs as speculated above would be the way to go. If the core counts can’t get that high, Fujitsu could push out the width of the SIMD units to – gasp – 1,024 bits.
No matter how the math crunching gets crammed into the future Fujitsu ARM chips, one thing is for sure. The memory bandwidth from HMC and from Tofu3 will have to increase – maybe by something on the order of 3X to 4X – to keep the cores and vector units all fed.
SOURCES- Nextplatform, Exascale

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.