
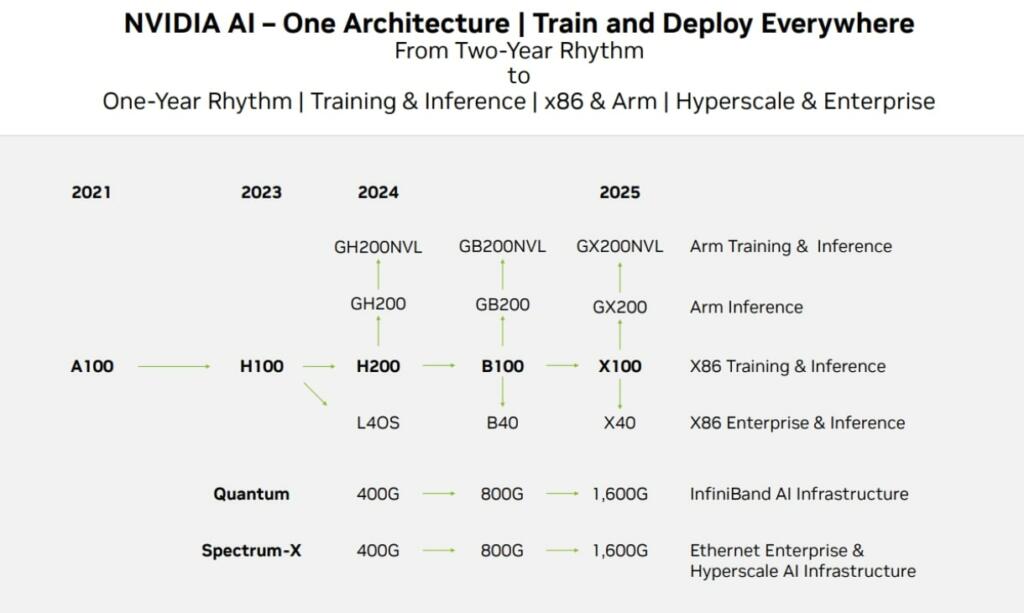
The NVIDIA H100 GPU has 30 teraflops of peak standard IEEE FP64 performance, 60 teraflops of peak FP64 tensor core performance, and 60 teraflops of peak FP32 performance. It also has a second-generation secure multi-instance GPU technology that makes it possible to partition the chip into seven smaller, fully isolated instances to handle multiple workloads simultaneously. FP8 can be used for AI.

![]()

The Nvidia H200 should double the H100 performance for large language model (LLM) AI.

Nvidia is set to adopt TSMC’s 3nm-class process technology in 2024 for the B-100. The B-100 will use about 1430 watts of power. The B-100 will have about 4 to 6 times the LLM performance of the H-100.
Kuwait is looking to use 700,000 Nvidia B-100 chips for an AI compute cluster using a gigawatt of power. This will likely scale to Zettaflops of compute.
Chip startup Tachyum has talked about 8 zettaflops of AI compute in 2025.



Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
I am not sure if this is amazing or this is terrifying
Is this an Nvidea ad? I would think you might mention something about the market, such as how AMD is much faster at FP64. I’m just asking for a little analysis rather than a marketing dump.