

Grok-1.5V is XAI’s first-generation multimodal model. In addition to its strong text capabilities, Grok can now process a wide variety of visual information, including documents, diagrams, charts, screenshots, and photographs. Grok-1.5V will be available soon to our early testers and existing Grok users.
Capabilities
Grok-1.5V is competitive with existing frontier multimodal models in a number of domains, ranging from multi-disciplinary reasoning to understanding documents, science diagrams, charts, screenshots, and photographs. Grok has capabilities in understanding our physical world. Grok outperforms its peers in our new RealWorldQA benchmark that measures real-world spatial understanding. For all datasets below, they evaluate Grok in a zero-shot setting without chain-of-thought prompting.

Writing Code from a Handdrawn Flowchart

Calories from Food Labels

Real-World Understanding
In order to develop useful real-world AI assistants, it is crucial to advance a model’s understanding of the physical world. Towards this goal, we are introducing a new benchmark, RealWorldQA. This benchmark is designed to evaluate basic real-world spatial understanding capabilities of multimodal models. While many of the examples in the current benchmark are relatively easy for humans, they often pose a challenge for frontier models.

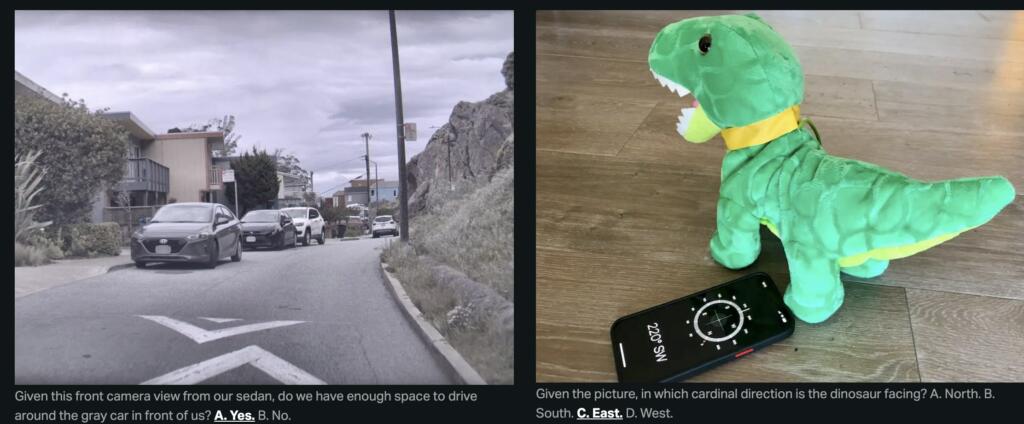
Into the future
Advancing both XAI multimodal understanding and generation capabilities are important steps in building beneficial AGI that can understand the universe. In the coming months, they anticipate to make significant improvements in both capabilities, across various modalities such as images, audio, and video.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
I see a lot of driving-relevant examples in the spatial reasoning section… might be related to X poaching Tesla AI engineers. Nothing wrong with Grok having good spatial understanding of course, but I’m not sure that it’s the most relevant skill for an AI chatbot.