

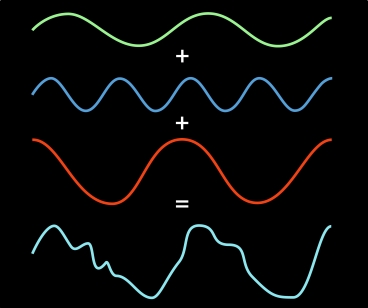
The Fourier transform is one of the most fundamental concepts in the information sciences. It’s a method for representing an irregular signal — such as the voltage fluctuations in the wire that connects an MP3 player to a loudspeaker — as a combination of pure frequencies. It’s universal in signal processing, but it can also be used to compress image and audio files, solve differential equations and price stock options, among other things.
Arxiv – Nearly Optimal Sparse Fourier Transform (27 pages)
The new algorithm — which associate professor Katabi and professor Piotr Indyk, both of MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), developed together with their students Eric Price and Haitham Hassanieh — relies on two key ideas. The first is to divide a signal into narrower slices of bandwidth, sized so that a slice will generally contain only one frequency with a heavy weight.
In signal processing, the basic tool for isolating particular frequencies is a filter. But filters tend to have blurry boundaries: One range of frequencies will pass through the filter more or less intact; frequencies just outside that range will be somewhat attenuated; frequencies outside that range will be attenuated still more; and so on, until you reach the frequencies that are filtered out almost perfectly.
If it so happens that the one frequency with a heavy weight is at the edge of the filter, however, it could end up so attenuated that it can’t be identified. So the researchers’ first contribution was to find a computationally efficient way to combine filters so that they overlap, ensuring that no frequencies inside the target range will be unduly attenuated, but that the boundaries between slices of spectrum are still fairly sharp.
Once they’ve isolated a slice of spectrum, however, the researchers still have to identify the most heavily weighted frequency in that slice. In the SODA paper, they do this by repeatedly cutting the slice of spectrum into smaller pieces and keeping only those in which most of the signal power is concentrated. But in an as-yet-unpublished paper, they describe a much more efficient technique, which borrows a signal-processing strategy from 4G cellular networks. Frequencies are generally represented as up-and-down squiggles, but they can also be though of as oscillations; by sampling the same slice of bandwidth at different times, the researchers can determine where the dominant frequency is in its oscillatory cycle.
Two University of Michigan researchers — Anna Gilbert, a professor of mathematics, and Martin Strauss, an associate professor of mathematics and of electrical engineering and computer science — had previously proposed an algorithm that improved on the FFT for very sparse signals. “Some of the previous work, including my own with Anna Gilbert and so on, would improve upon the fast Fourier transform algorithm, but only if the sparsity k” — the number of heavily weighted frequencies — “was considerably smaller than the input size n,” Strauss says. The MIT researchers’ algorithm, however, “greatly expands the number of circumstances where one can beat the traditional FFT,” Strauss says. “Even if that number k is starting to get close to n — to all of them being important — this algorithm still gives some improvement over FFT.”
We consider the problem of computing the k-sparse approximation to the discrete Fourier transform of an n-dimensional signal. We show:
* An O(k log n)-time algorithm for the case where the input signal has at most k non-zero Fourier coefficients, and
* An O(k log n log(n / k))-time algorithm for general input signals.
Both algorithms achieve o(n log n) time, and thus improve over the Fast Fourier Transform, for any k = o(n). Further, they are the first known algorithms that satisfy this property. Also, if one assumes that the Fast Fourier Transform is optimal, the algorithm for the exactly k-sparse case is optimal for any k = n^{ Omega(1)} . We complement our algorithmic results by showing that any algorithm for computing the sparse Fourier transform of a general signal must use at least Omega(k log(n/k) / log log n) signal samples, even if it is allowed to perform adaptive sampling.
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.