
Real world Technologies – IBM’s Blue Gene/Q conclusively demonstrates that a CPU designed for throughput can match and even exceed the power efficiency of GPUs. There is still a gap in terms of area efficiency, but smaller than the data suggests given that Blue Gene/Q includes a large cache and robust interconnects that are not found in a GPU. This bodes relatively well for Intel’s Knights Corner, although the area problems might be worse with the overhead for x86 relative to PowerPC.
The best throughput processor (Fermi) has a 68% area and 77% power advantage compared to the best CPU (Ivy Bridge), despite using an older process technology. Excluding the GPU die area from Ivy Bridge, and the density advantage falls to a little under 10%. While the two design philosophies may be converging, they are also more clearly delineated as throughput processors have become more successful at handling double precision floating point. There are no cases of GPUs that are less efficient than CPUs.
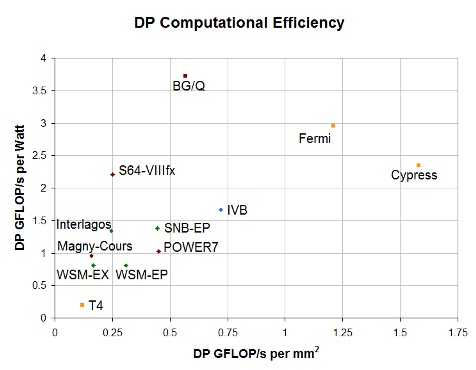
The comparison between Interlagos and Magny-Cours is also fairly instructive. This transition combines a substantial architectural change and a shrink from a conventional 45nm process to a 32nm process featuring high-k/metal gate transistors. From a theoretical standpoint, the unusual philosophy behind Bulldozer seems to be a success. The performance density jumped by about 50%, while the total cache capacity increased by a similar factor. However, performance/watt only grew by 39%. In contrast, Intel claimed that the 45nm HKMG process provided a 30% decrease in active power. Given the numerous improvements in Bulldozer, it is hard to imagine that the new architecture only improved compute/watt by a mere 7%. This implies that Global Foundries’ 32nm process is leaving performance on the table, which is consistent with reports on the difficulties associated with the gate first approach to transistor formation.
Looking to the Future
In late 2012 and early 2013, there should be a number of new products that change the overall picture. While the first GPUs from AMD and Nvidia using TSMC’s 28nm process have already been released, the compute variants are still under development and expected at the end of 2012. Moving to a new process technology should yield at least 50% across the board. Intel’s Knights Corner will also arrive, the first opportunity to evaluate an x86-based throughput processor. Realistically, these new products should widen the gap between CPUs and throughput processors.
The other major development expected in the near future is the emergence of microservers based on extremely low-power x86 and ARM processors. Calxeda has already started shipping a server based on a quad-core A9, however the target market is really scale-out workloads with little floating point. Eventually, Calxeda will upgrade to the higher performance ARM A15 which supposedly can execute 4-8 FLOPs per cycle. Applied Micro is designing a custom ARM core that targets the server market, although it may not ship till late in 2013. The traditional x86 vendors are also expected to release servers based around low-power designs. Intel’s Centerton is slated for 2012 and AMD’s acquisition of SeaMicro will eventually yield optimized SoC designs. In theory, these offerings may shift the compute efficiency spectrum, by sacrificing single threaded performance to improve throughput. However, the results are for from clear at the moment and the next year should be quite interesting to watch while we wait to revisit this topic.
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.