
The TaihuLight supercomputer is being harnessed for some interesting work on deep neural networks. What is fascinating here is that currently, the inference side of such workloads can scale to many processors, but the training side is often scale-limited hardware and software-wise.
Fu described an ongoing project on the Sunway TaihuLight machine to develop an open source deep neural network library and make the appropriate architectural optimization for both high performance and efficiency on both the training and inference parts of deep learning workloads. “Based on this architecture, we can provide support for both single and double precision as well as fixed point,” he explains. The real challenge, he says, is to understand why most existing neural network libraries cannot benefit much from running at large scale and looking at the basic elements there to get better training results over a very large number of cores.
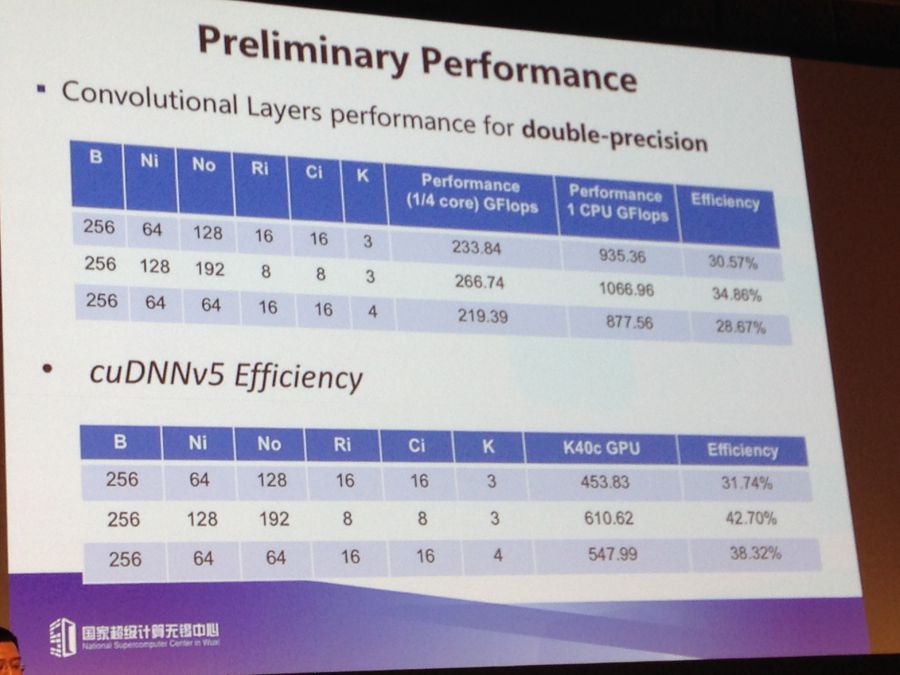
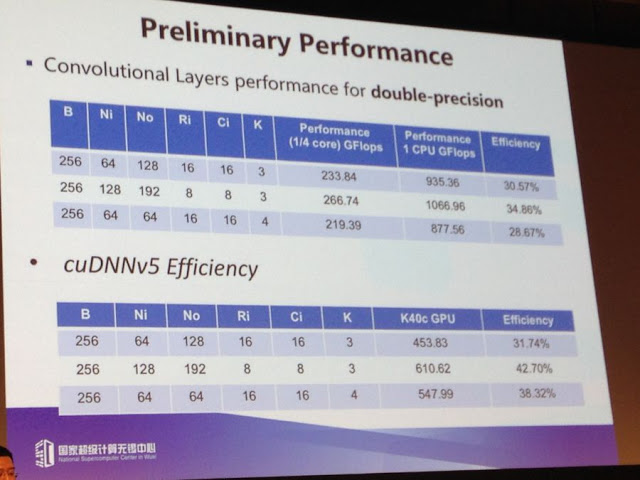
Above are some noteworthy preliminary performance results for convolutional layers for double-precision. The efficiency isn’t outstanding (around 30%A) but Fu says they’re working on the library to bolster it and get equal or better performance than the GPU—the standard thus far for training.
Andrew Ng, Chief Scientist at Baidu’s Silicon Valley Lab and well-known AI guru, noted during his keynote at ISC16, training a speech recognition like the one at Baidu takes around 10 exaflops of compute for the entire cycle across 4 terabytes of data. That kind of scale of compute and data management is only found in HPC, and this is, as Ng said to the audience, “where machine learning could really use HPC’s help”.
Training deep neural networks is very computationally intensive: training one of Baidu’s models takes tens of exaflops of work, and so HPC techniques are key to creating these models.
The faster we train our networks, the more iteration we can make on our datasets and models, and the more iterations we make, the more we advance our machine learning. This means that HPC translates into machine learning progress, which is why we have adopted the HPC point of view. Machine learning should embrace HPC. These methods will make researchers more efficient and help accelerate the progress of our whole field.
Outside of research interest, AI really has not arrived for HPC–and even browsing the research poster sessions at ISC to see what’s next for HPC, most were focused on MPI, scalability, and other “run of the mill” problems and applications.
There are already some areas where traditional supercomputing centers are branching into machine learning and deep neural networks to advance scientific discovery. For instance, this is useful in image recognition for weather and climate modeling as well as for a few other areas, as noted by Intel in their opening up about an upcoming focus on machine learning, that attach to existing HPC workflows.
AI has made tremendous progress, and Ng is optimistic about building a better society that is embedded up and down with machine intelligence. But AI today is still very limited. Almost all the economic and social value of deep learning is through “supervised learning,” which is limited by the amount of suitably formatted (i.e., labeled) data. Looking ahead, there are many other types of AI beyond supervised learning that Ng finds exciting, such as unsupervised learning (where we have a lot more data available, because the data does not need to be labeled). There’s a lot of excitement about these other forms of learning in our group and others.
SOURCES – Nextplatform

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.