

BitNet is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.
The work was done by Microsoft Research and Chinese Academy of Science researchers.
The model not only used up to 7 times less memory but were also up to 4 times faster on latency. This improvement is mainly about memory usage being more efficient and smaller models in memory size having the same performance or more performance. I think the demand for AI capabilities and the various compute capabilities is insatiable for the foreseeable future. I do not think this will negatively impact Nvidia chip demand or its valuation.
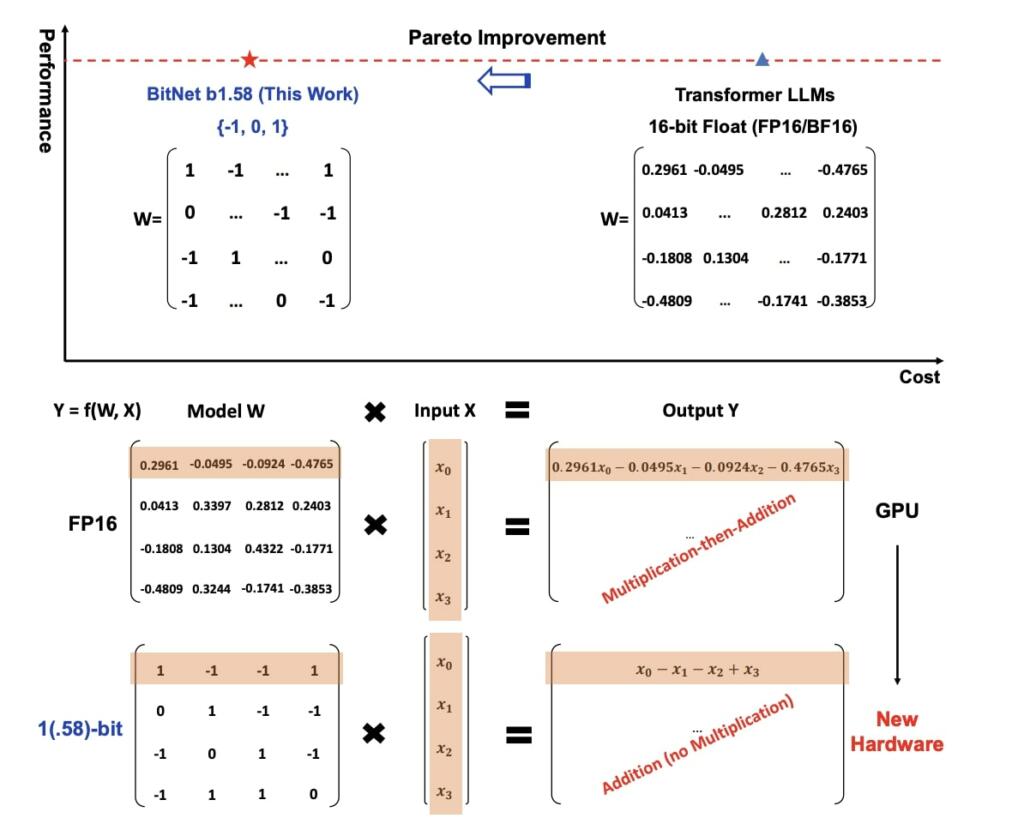

BitNet b1.58 is enabling a new scaling law with respect to model performance and inference cost.
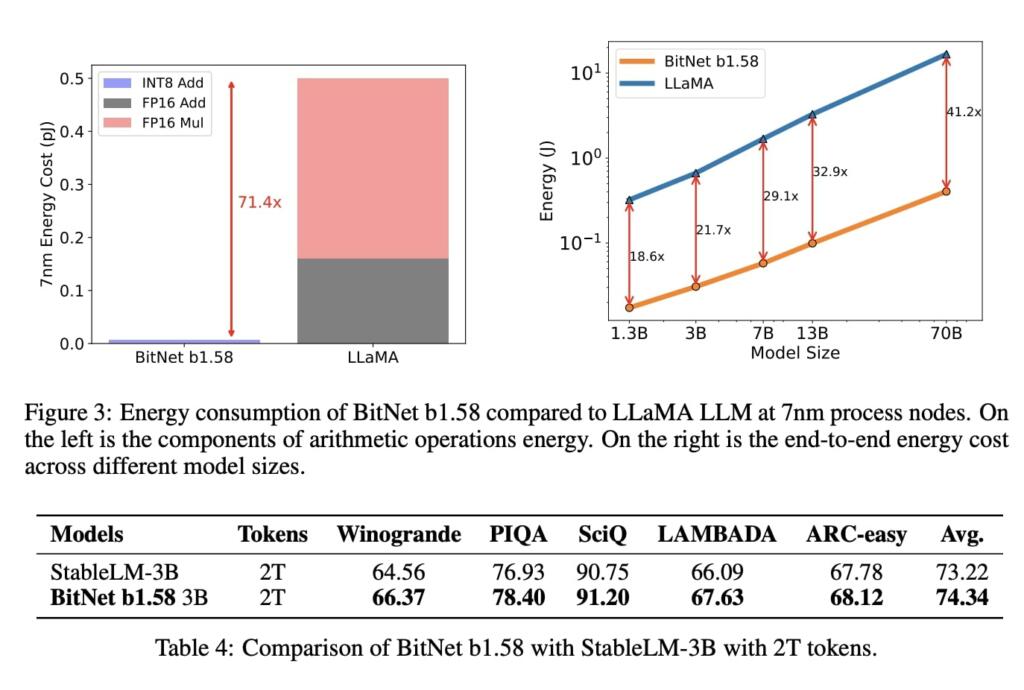
• 13B BitNet b1.58 is more efficient, in terms of latency, memory usage and energy consumption, than 3B FP16 LLM.
• 30B BitNet b1.58 is more efficient, in terms of latency, memory usage and energy consumption, than 7B FP16 LLM.
• 70B BitNet b1.58 is more efficient, in terms of latency, memory usage and energy consumption, than 13B FP16 LLM.
They trained a BitNet b1.58 model with 2T (2 Trillion) tokens following the data recipe of StableLM-3B [TBMR], which is the state-of-the-art open-source 3B model.
New Hardware for 1-bit LLMs
Recent work like Groq5 has demonstrated promising results and great potential for building specific hardware (e.g., LPUs) for LLMs. Going one step further, we envision and call for actions to design new hardware and system specifically optimized for 1-bit LLMs, given the new computation paradigm enabled in BitNet.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
In theory, one could implement any function (including that which an LLM represents) using single bit inputs and weights and only XOR functions. That might allow for the ultimate compaction and performance.
This looks like a huge deal. Order of magnitude scale down in power, chip area and memory needed, not to mention increased processing speed (lower reaction time) will have profound implications for robotics and AI in general. Largely eliminating multiplication from inference as they have means human level AI processing on optimized GPUs using current processes.
does it means that NVIDIA is overvalued?
this is mainly about memory usage being more efficient and smaller models in memory size having the same performance or more performance. I think the demand for AI capabilities and the various compute capabilities is insatiable for the foreseeable future. I do not think this will negatively impact Nvidia chip demand or its valuation.
It would only intensify demand for Nvidia NN training clusters like Blackwell because it would promise an eventual revolution in the capability and cost of inference hardware that does the work locally. This promises AIs running everywhere cheap but they still have to be trained. Nvidia would likely be at the forefront of new hardware designs for 1 bit inference engines too but it would be a more open playing field.