
Scaling Transformer to Output Over 2 Million Words With RMT
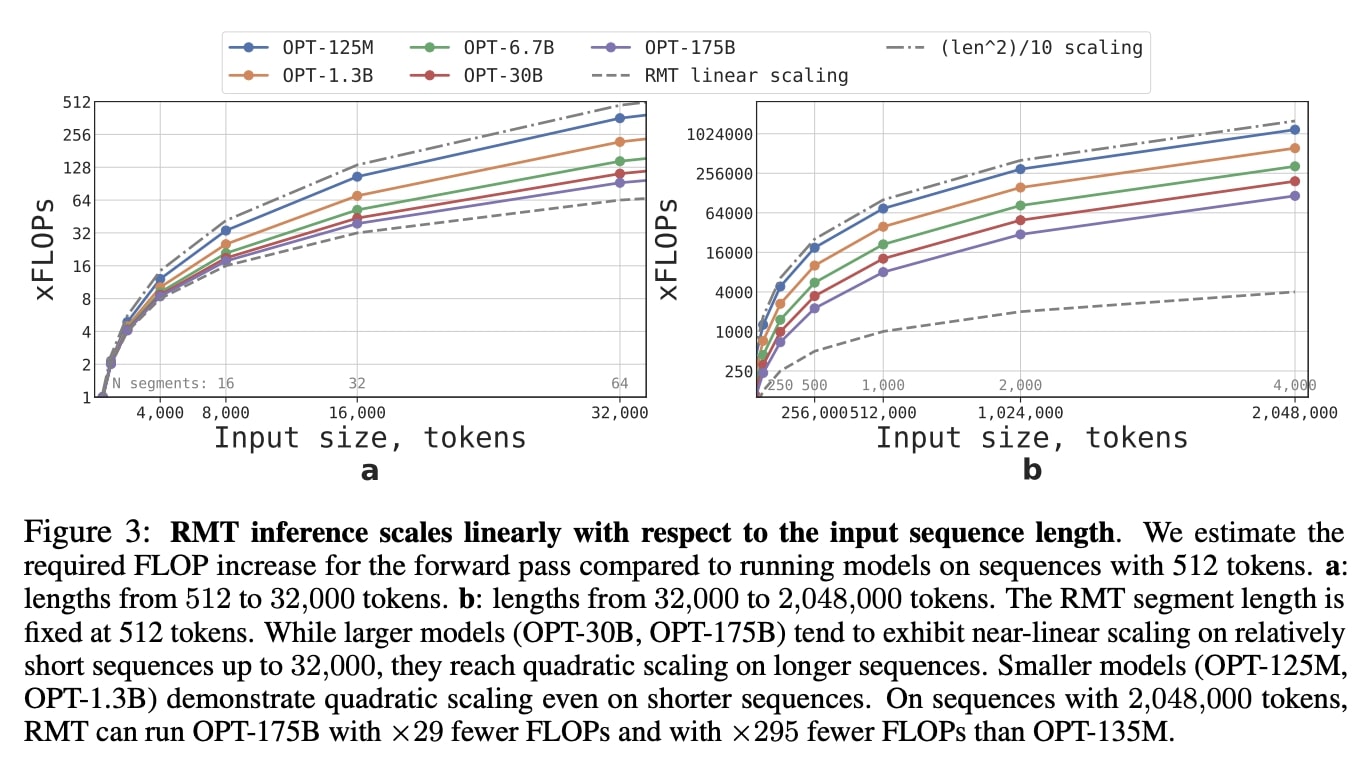
Recurrent Memory Transformer retains information across up to 2 million tokens (words). Applying Transformers to long texts does not necessarily require large amounts of memory. By employing a recurrent approach and memory, the quadratic complexity can be reduced to linear. The models trained on sufficiently large inputs can extrapolate their abilities to texts orders of …