
Recurrent Memory Transformer retains information across up to 2 million tokens (words). Applying Transformers to long texts does not necessarily require large amounts of memory. By employing a recurrent approach and memory, the quadratic complexity can be reduced to linear. The models trained on sufficiently large inputs can extrapolate their abilities to texts orders of magnitude longer. Synthetic tasks explored in this study serve as the first milestone for enabling RMT to generalize to tasks with unseen properties, including language modelling. In future work, the researchers aim to tailor the recurrent memory approach to the most commonly used Transformers to improve their effective context size.
This enables the LLM (Large Language Models) to output long novels.
Les Miserables by Victor Hugo has about 545,000 words.
The total Harry Potter (by JK Rowling) series word count is 1,084,625 words.
Lord of the Rings by JRR Tolkien is 550,000 words.
The current five novels of the Game of Thrones series is nearly 1.74 million words.
The 14 books in the Wheel of Time by Robert Jordan is almost 4.3 million words.
War and Peace by Tolstoy has 587,287 words.
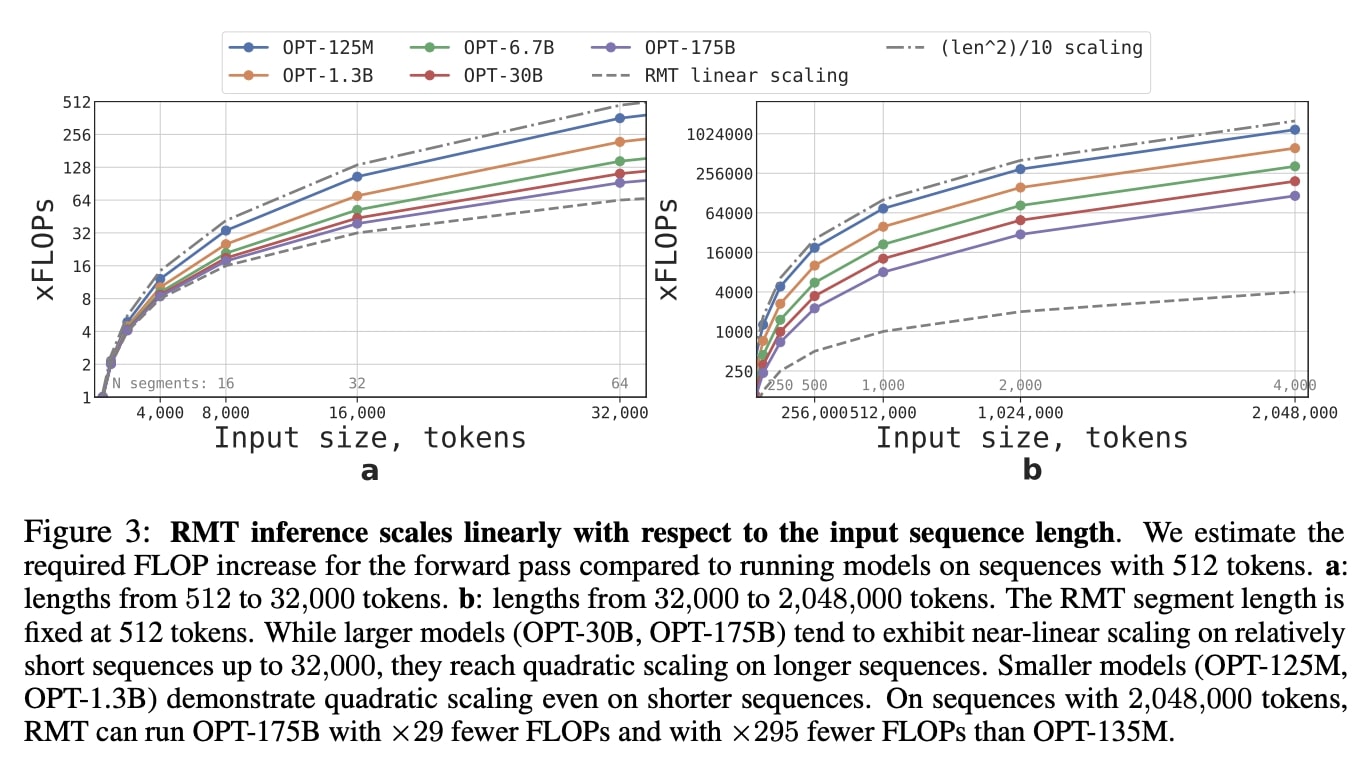
By leveraging the Recurrent Memory Transformer architecture, researchers have successfully increased the model’s effective context length to an unprecedented two million tokens, while maintaining high memory retrieval accuracy. The method allows for the storage and processing of both local and global information and enables information flow between segments of the input sequence through the use of recurrence. The approach holds significant potential to enhance long-term dependency handling in natural language understanding and generation tasks as well as enable large-scale context processing for memory-intensive applications.

Scaling Transformer to 1M tokens and beyond with RMT
Recurrent Memory Transformer retains information across up to 2 million tokens.
During inference, the model effectively utilized memory for up to 4,096 segments with a total length of 2,048,000 tokens—significantly exceeding… pic.twitter.com/Axggo0nSoH
— AK (@_akhaliq) April 24, 2023
Other AI Developments This Past Week
Monday:
-Adobe adds Firefly to video editing
-Elon Musk reveals TruthGPT
-ChatGPT got featured in a new NBA commercial
-Meta AI released DINOv2More details:https://t.co/Ux00As8JSz
— Rowan Cheung (@rowancheung) April 24, 2023

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.