

It is a table of mission parameters calculated by Jon C. Rogers for the book Spaceship Handbook.
Six trajectories are listed
Three impulse (rocket) types and three constant acceleration brachistochrone types.
“Impulse” means the spacecraft makes an initial burn then coasts for months, which is a standard rocket mission.
Impulse trajectory I-1 is pretty close to a Hohmann (minimum delta V / maximum time) orbit, but with a slightly higher delta V.
Impulse trajectory I-2 is in-between I-1 and I-3 (it is equivalent to an elliptical orbit from Mercury to Pluto, the biggest elliptical orbit that will fit inside the solar system).
Impulse trajectory I-3 is near the transition between delta V levels for high impulse trajectories and low brachistochrone trajectories (it is a hyperbolic solar escape orbit plus 30 km/s).
Brachistochrone (maximum delta V / minimum time) trajectories are labeled by their level of constant acceleration: 0.01 g, 0.10 g, and 1.0 g.

Elon Musk of Spacex talked about achieve 30 days on a one way trip to Mars with the Interplanetary Transport system. This would be the Impulse Trajectory I-2, with with about 52 km per second delta V.
I think to achieve the 30 day one way trip time, Spacex would be assembling an even larger rocket system in orbit using multiple trips from Earth to a staging area for Mars.


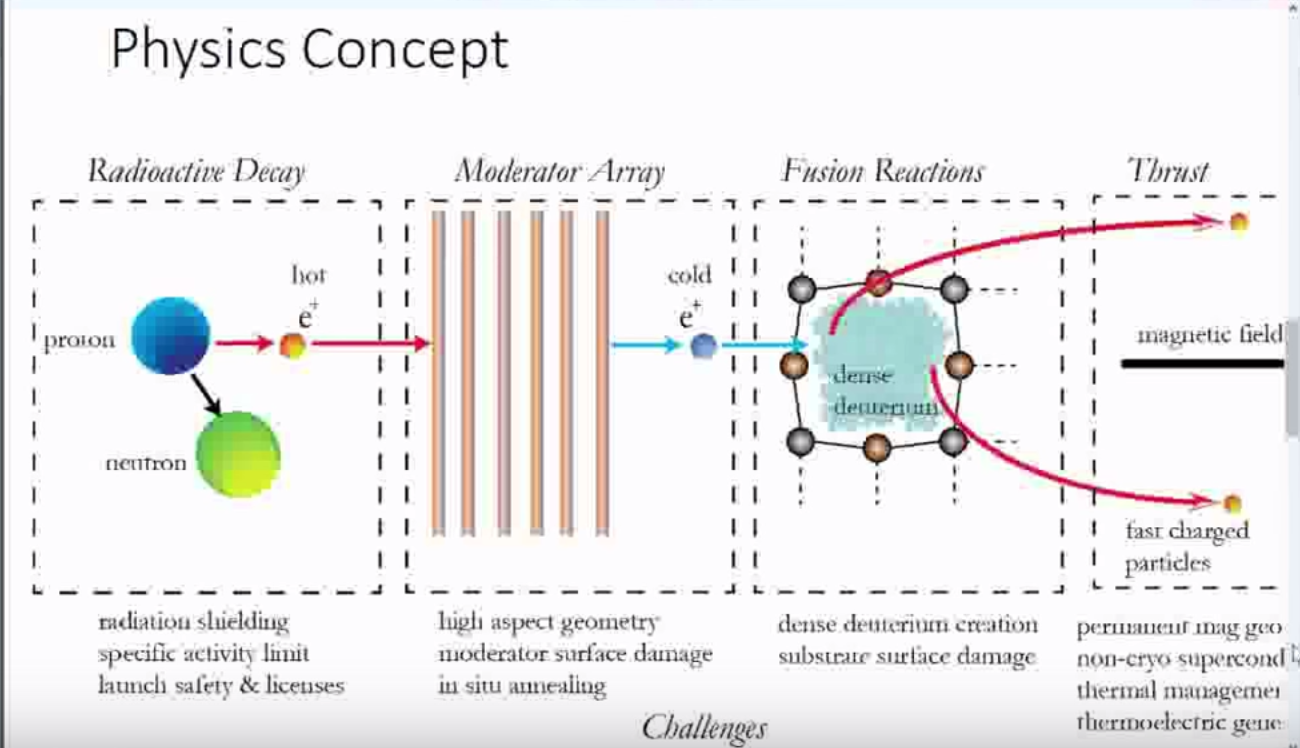
Constant acceleration could be achieved with an antimatter catalyzed fusion propulsion system like Positron Dynamics is developing
15 days one way to Mars with a constant 0.01 G acceleration and deceleration.
6 days one way to Mars with a constant 0.1G acceleration and deceleration.
2 days one way to Mars with a constant 1G acceleration and deceleration.
Positron Dynamics is looking at antimatter catalyzed fusion for propulsion.
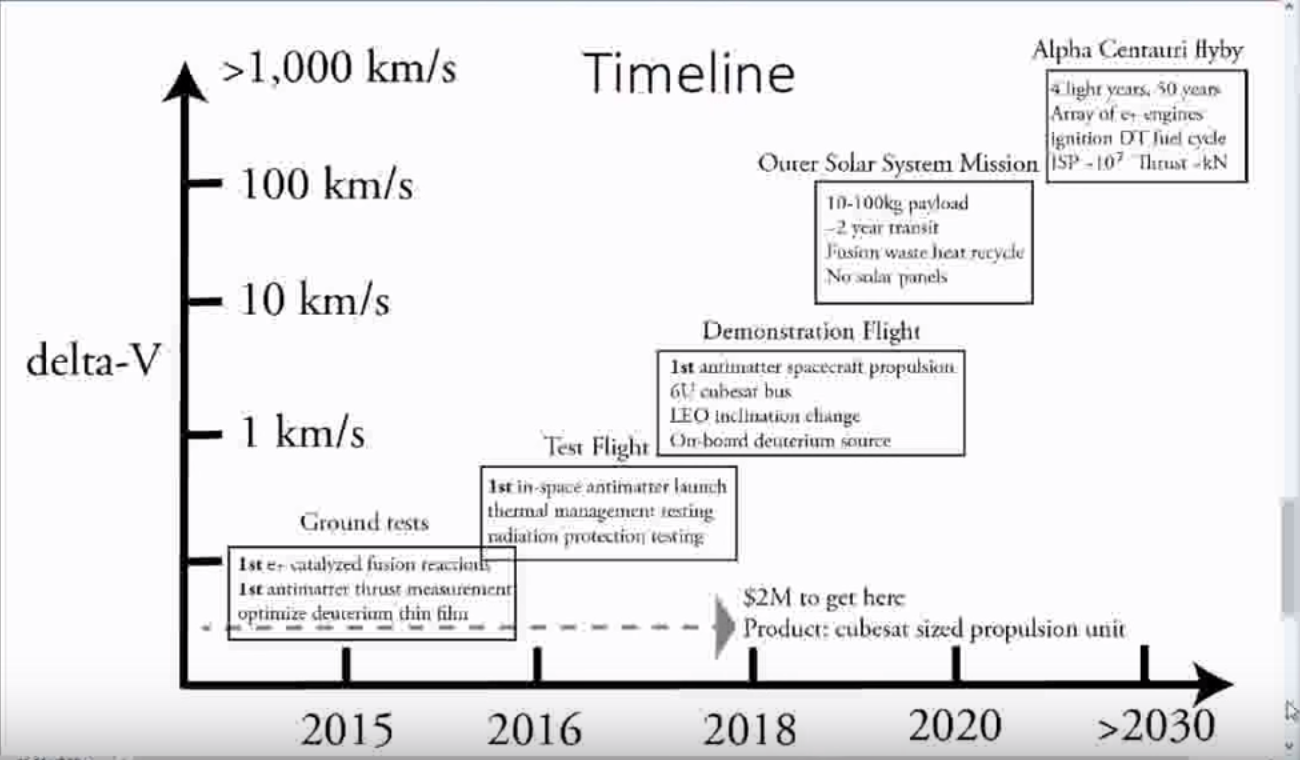
* within 2 year they want to make 6U cubesat that they will use to test the propulsion in space. It will be generating 100s of watts
* the propulsion will have delta V of 1 to 10 km/second
* Later systems will have more delta V and enable cubesats and small satellites to stay in orbit for years instead of days
* the cubesats with propulsion will enable very low orbit internet satellites


* in the 2020s if things go well they will be able to scale to 10 km/second to 100 km/second with 10-100 kilogram payloads for small probe exploration of the solar system
* Later beyond 2030, they will have regenerative isotopes for a lot more power and achieve ten million ISP and several kilonewtons of propulsive force
* could enable 1G acceleration and deceleration propulsion which would 3.5 weeks to Pluto


Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.