

Stephen McAleese, at Less Wrong, used scaling rules and formulas to try to predict the performance of GPT-4. He underpredicted the capabilities of GPT-4. However, he was not widely wrong. GPT-4 came out earlier than he expected and had better performance than expected.
Multi-task Language Understanding on MMLU was better than expected. GPT-4 can work with images and not just text.
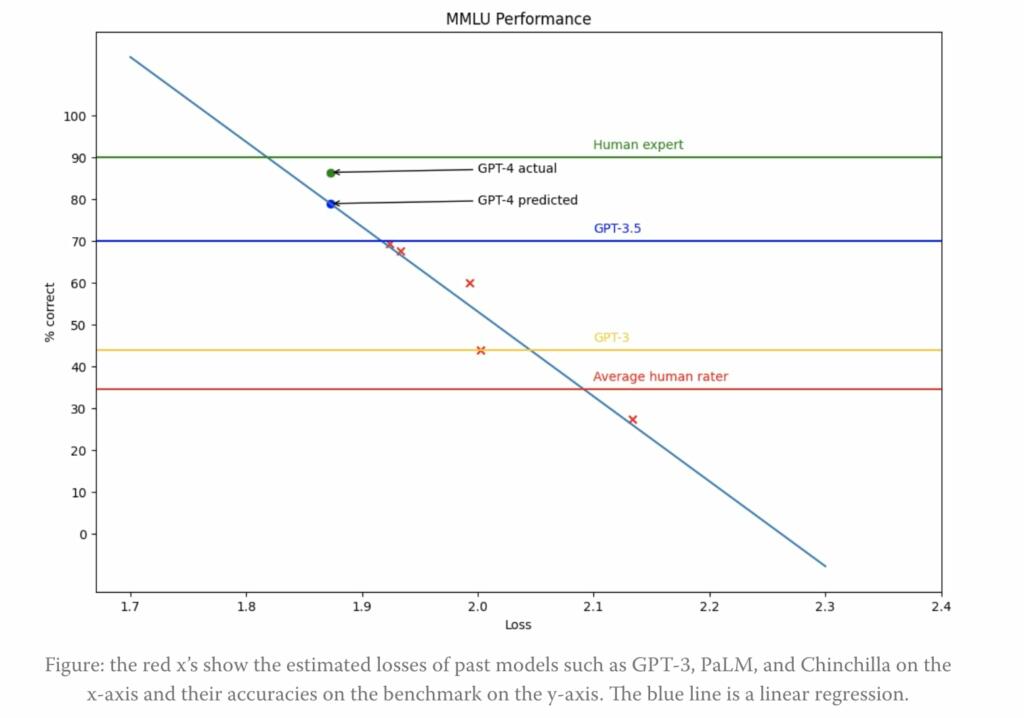
GPT-4 is doing very well on SAT, GMAT, LSAT and many other tests.
Stephen indicates that he ignored algorithmic advances such as the introduction of image inputs to the GPT-4 model. Not taking algorithmic advances into account could also explain why he underestimated GPT-4’s performance improvement on the MMLU benchmark. The scaling prediction alone would always underpredict the improvements. Algorthmic advances will speed up improvement.
The average capabilities of language models tend to scale smoothly given more resources, specific capabilities can increase abruptly because of emergent capabilities. Therefore, a model that predicts linear improvements on certain capabilities in the short term could merely be a short tangent in a more complex non-linear model. This suggests that predicting specific capabilities in the long term is significantly more difficult.
There will be an increased effect of algorithmic advances on ML capabilities in the long term. More money and more cleverness from developers could overcome plateauing of improvements.
Given the breadth and depth of GPT-4’s capabilities, it can reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system.
There is a 154 page analysis of GPT-4. Sparks of Artificial General Intelligence: Early experiments with GPT-4 by Microsoft Research.
They have focused on the surprising things that GPT-4 can do, but we do not address the fundamental questions of why and how it achieves such remarkable intelligence. How does it reason, plan, and create? Why does it exhibit such general and flexible intelligence when it is at its core merely the combination of simple algorithmic components—gradient descent and large-scale transformers with extremely large amounts of data? These questions are part of the mystery and fascination of LLMs, which challenge our understanding of learning and cognition, fuel our curiosity, and motivate deeper research. Key directions include ongoing research on the phenomenon of emergence in LLMs.
The central claim of our work is that GPT-4 attains a form of general intelligence, indeed showing sparks of artificial general intelligence. This is demonstrated by its core mental capabilities (such as reasoning, creativity, and deduction), its range of topics on which it has gained expertise (such as literature, medicine, and coding), and the variety of tasks it is able to perform (e.g., playing games, using tools, explaining itself,…). A lot remains to be done to create a system that could qualify as a complete AGI. We conclude this paper by discussing several immediate next steps, regarding defining AGI itself, building some of missing components in LLMs for AGI, as well as gaining better understanding into the origin of the intelligence displayed by the recent LLMs.
On the path to more general artificial intelligence
Some of the areas where GPT-4 (and LLMs more generally) should be improved to achieve more general intelligence include (note that many of them are interconnected):
• Confidence calibration: The model has trouble knowing when it should be confident and when it is just guessing. It both makes up facts that have not appeared in its training data, and also exhibits inconsistencies between the generated content and the prompt, which we referred to as open-domain and closed-domain hallucination in Figure 1.8.

These hallucinations can be stated in a confident and persuasive manner that can be difficult to detect. Thus, such generations can lead to errors, and
also to confusion and mistrust. While hallucination is a good thing when generating creative content, reliance on factual claims made by a model with hallucinations can be costly, especially for uses in high-stakes domains such as healthcare. There are several complementary ways to attempt to address hallucinations. One way is to improve the calibration of the model (either via prompting or fine-tuning) so that it either abstains from answering when it is unlikely to be correct or provides some other indicator of confidence that can be used downstream. Another approach, that is suitable for mitigating open-domain hallucination, is to insert information that the model lacks into the prompt, for example by allowing the model to make calls to external sources of information, such as a search engine as in Section 5.1. For closed-domain hallucination the use of additional model computation through post-hoc checks is also promising, see Figure 1.8 for an example. Finally, building the user experience of an application with the possibility of hallucinations in mind can also be part of an effective mitigation strategy.
• Long-term memory: The model’s context is very limited (currently 8000 tokens, but not scalable in terms of computation), it operates in a “stateless” fashion and there is no obvious way to teach the model new facts. In fact, it is not even clear whether the model is able to perform tasks which require an evolving memory and context, such as reading a book, with the task of following the plot and understanding references to prior chapters over the course of reading.
• Continual learning: The model lacks the ability to update itself or adapt to a changing environment. The model is fixed once it is trained, and there is no mechanism for incorporating new information or feedback from the user or the world. One can fine-tune the model on new data, but this can cause degradation of performance or overfitting. Given the potential lag between cycles of training, the system will often be out of date when it comes to events, information, and knowledge that came into being after the latest cycle of training.
• Personalization: Some of the applications require the model to be tailored to a specific organization or end user. The system may need to acquire knowledge about the workings of an organization or the preferences of an individual. And in many cases, the system would need to adapt in a personalized manner over periods of time with specific changes linked to the dynamics of people and organizations. For example, in an educational setting, there would be an expectation of the need for the system to understand particular learning styles as well as to adapt over time to a student’s progress with comprehension and prowess. The model does not have any way to incorporate such personalized information into its responses, except by using meta-prompts, which are both limited and inefficient.
• Planning and conceptual leaps: the model exhibits difficulties in performing tasks that require planning ahead or that require a “Eureka idea” constituting a discontinuous conceptual leap in the progress towards completing a task. In other words, the model does not perform well on tasks that require the sort of conceptual leaps of the form that often typifies human genius.
• Transparency, interpretability and consistency: Not only does the model hallucinate, make up facts and produce inconsistent content, but it seems that the model has no way of verifying whether or not the content that it produces is consistent with the training data, or whether it’s self-consistent. While the model is often able to provide high-quality post-hoc explanations for its decisions, using explanations to verify the process that led to a certain decision or conclusion only works when that process is accurately modeled and a sufficiently powerful explanation process is also accurately modeled. Both of these conditions are hard to verify, and when they fail there are inconsistencies between the model’s decisions and its explanations. Since the model does not have a clear sense of its own limitations it makes it hard to establish trust or collaboration with the user without extensive experimentation in a narrow domain.
• Cognitive fallacies and irrationality: The model seems to exhibit some of some of the limitations of human knowledge and reasoning, such as cognitive biases and irrationality (such as biases of confirmation, anchoring, and base-rate neglect) and statistical fallacies. The model may inherit some of the biases, prejudices, or errors that are present in its training data, which may reflect the distribution of opinions or perspectives linked to subsets of the population or larger common views and assessments.
• Challenges with sensitivity to inputs: The model’s responses can be very sensitive to details of the framing or wording of prompts and their sequencing in a session. Such non-robustness suggests that significant effort and experimentation is often required with engineering prompts and their sequencing and that uses in the absence of such investments of time and effort by people can lead to suboptimal and non-aligned inferences and results.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.
I still regard it more as what I would call cognitive automation. It takes routine thinking and automates it.
The industrial revolution might be considered physical automation.
Skilled and/or educated humans are still needed to do the non-routine stuff.
Someday that may change, but probably not until we can make AGI, strong-AI, or Synthetic Intelligence, such that it is able to convince us that it is no different from a human in a box.
At which point we may have to settle on a definition for “What is human?” by merely stating that a human is defined by its actions.
Any reading of a report from LessWrong has to allow for the fact that they are the public face of what could be described as the techno-cult. For years they have been convinced as a matter of faith that superintelligent AI is just around the corner and they regard it as a god waiting to be born. The thinking of their leader, Eliezer Yudkowsky, is informed mainly by sci-fi writers (in particular Vernor Vinge), since he lacks the education or experience to program himself or to directly understand machine learning research.
There may be something of use in McAleese’s report, but the culture at LessWrong is greatly biased towards their desired conclusions.
“…AI is just around the corner…”
In fact this appears to be true if your “just around the corner” is longer than “right now”. The acceleration of these things is remarkable. As fast as things are changing, what will they be like in five years? Scary.
And they will continue to progress because the power of these to make people profits could be immense, or they could kill us all, but greed will prevail no matter what. Anyone who doesn’t build them will lose out, so all the major players will feel they have to, no matter the consequences or risk.
So far their mental model seems to be the same as psychopaths, and we already have a vast, huge problem with them now. God like mental power psychopaths, just what we need.
There has never been a technological advance that was prevented by legislation. Certainly not one that had positive economic ramifications for those implementing it.
If we want to get a handle on how it is used and developed, we will need to look for opportunities that make preferred outcomes desirable.
We certainly don’t want to involve a bunch of clueless politicians trying to issue a mandate on something they don’t even understand, but that their lobbyists are pushing them to do.
Yes, it is weak AGI, but AGI nonetheless. Doesn’t matter if it doesn’t have desires or intentions other than complete our prompts.
It can take any kind of problem and tacke it with different degrees of success. For some, it’s superhumanly good, for other passable, and for many others it stinks. But we are already far away from the dumb chat bot territory.
Seems we found the holy grail we have beek looking for, and it will only get better.
But it’s not human style intelligence. It’s more like insect style: No real capacity for learning, doesn’t understand anything at all, but has a vastly comprehensive set of reflexes and instincts that allow mimicking intelligence.
“GPT-4 can work with images, video and sound and not just text”
Brian, I don’t know why are you repeating this. This is not true. This was pre release rumour.
Just like “It will have 100T parameters” rumour
GPT-4 only works with:
text – to text
and image to text modalities (it describes what it sees on uploaded pictures)
No video, no sound in GPT-4.
I think GPT-5 will have those capabilities
Brian is amazing at finding provocative viewpoints and information; he is less strong in analyzing their credibility. Some readers may remember the months (years?) of e-cat articles in which this blog fawned on a con artist’s promises of an energy revolution. GoatGuy was the only voice of reason in those days.
I do miss Goatguy.
Why aren’t facts categorized with percentages for the possibility of misinterpretation/faults (false negatives, false positives) on the human?ai interface?
Then interpretation of ‘input thesis’ and ‘training model database’ would be varied for optimizing results?
Then going back from best available answer to a most suitable input thesis might support suggesting what question to ask for optimized results?
Yes, some kind of iterative and less intelligent (what otherwise would avoid iteration or feedback, because of ‘forward error correction’ through improved knowledge (database)?)
Just sounds like the next bubble to me. Watch this swell into a trillion dollar balloon when the real traction is to be had in a better help desk or better internet searches.
You are goi g to be very very wrong on that.
Can such systems seek out new information? Have they demonstrated curiosity? Can they solve problems by identifying problems first or are they just answering questions? I think they are remarkably simulations of intelligence and that will be very valuable but I think there is another qualitative leap to get to general intelligence.
“There will be an increased effect of algorithmic advances on ML capabilities in the long term. More money and more cleverness from developers could overcome plateauing of improvements.”
If everything is working as expected and this is true AGI, the cleverness should come from the algorithm itself and a virtuous feedback loop (The Singularity!) will be established.